Q. 여러 csv파일을 가져와 한 개의 dataframe에 나타내고 싶으면?
A) 👇 glob package의 glob module 사용!
from glob import glob
♣ glob docu 👇👇 ♣
https://docs.python.org/3/library/glob.html
▧ glob module ▧
"The glob module finds all the pathnames matching a specified pattern according to the rules used by the Unix shell, although results are returned in arbitrary order(그래서 glob쓰면 sorted() 추천!). No tilde expansion is done, but *, ?, and character ranges expressed with [] will be correctly matched. This is done by using the os.scandir() and fnmatch.fnmatch() functions in concert, and not by actually invoking a subshell. Note that unlike fnmatch.fnmatch(), glob treats filenames beginning with a dot (.) as special cases. (For tilde and shell variable expansion, use os.path.expanduser() and os.path.expandvars().)"
▧ glob.glob method ▧
"Return a possibly-empty list of path names that match pathname, which must be a string containing a path specification. pathname can be either absolute (like /usr/src/Python-1.5/Makefile) or relative (like ../../Tools/*/*.gif)(절대경로, 상대경로 다 불러올 수 있슴), and can contain shell-style wildcards. Broken symlinks are included in the results (as in the shell). Whether or not the results are sorted depends on the file system. If a file that satisfies conditions is removed or added during the call of this function, whether a path name for that file be included is unspecified."
glob.glob(pathname, *, root_dir=None, dir_fd=None, recursive=False)
1> 주유소 관련 csv파일들을 불러온다
→ 필자 data folder에는 '과거_판매가격(주유소)_2018.csv' & '과거_판매가격(주유소)_2019.csv' & '과거_판매가격(주유소)_2020.csv' & 과거_판매가격(주유소)_2021.csv'의 이름이 비슷한 주유소 관련 data csv 파일이 4개가 있다.
- 일일이 csv파일들을 불러와 합치기엔 시간이 많이 걸린다.
2> glob를 사용해 file name list를 만든다 (이 때 glob는 arbitrary order로 return하므로 sorted() 사용하여 file name 정렬!)
oil_files = sorted(glob('../data/과거_판매가격(주유소)_20**.csv'))
oil_files
'''
['../data\\과거_판매가격(주유소)_2018.csv',
'../data\\과거_판매가격(주유소)_2019.csv',
'../data\\과거_판매가격(주유소)_2020.csv',
'../data\\과거_판매가격(주유소)_2021.csv']
'''- row-wise-
3> 이제 for 문을 돌려 read_csv()로 읽어들이고 concat을 사용해 하나의 dataframe으로 합친다
(ignore_index값 True로 설정해서 index 순서를 0부터 오름차순으로 배열)
(concat 관련 데이터 합치기 (data manipulation) posting 별도 참고..!)
pd.concat((pd.read_csv(file) for file in oil_files),ignore_index=True)
4> 완성!
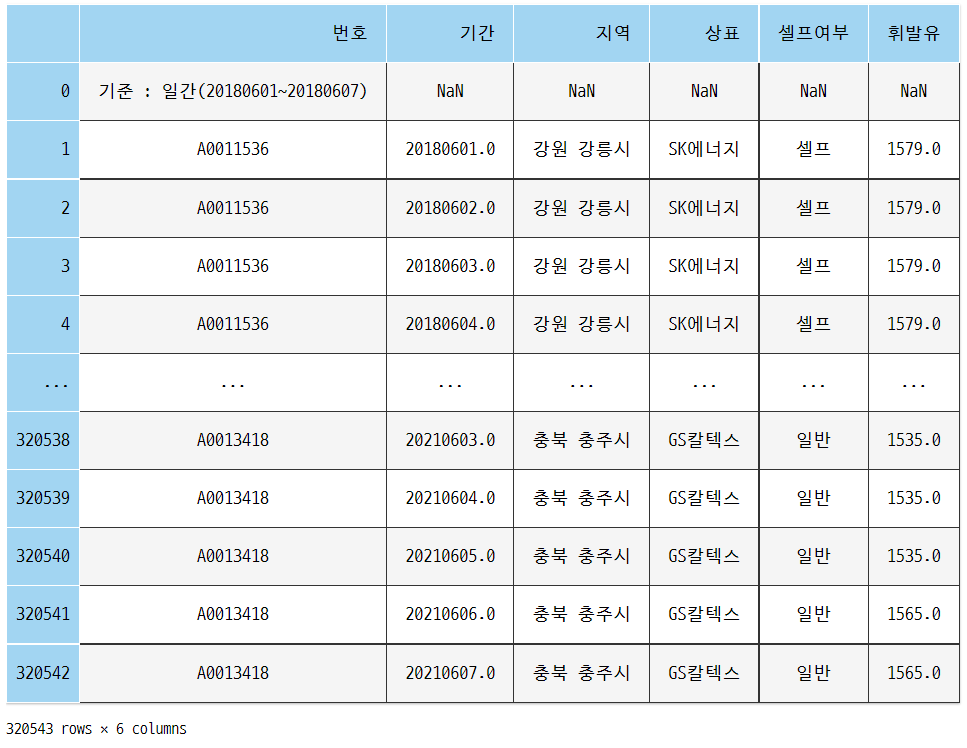
- column-wise-
5> concat의 default는 행 방향으로 아래 행부터 채워준다. 만약에 열 방향으로 채우고 싶다면 'axis='columns' 추가
- 행이 늘어나진 않으므로 index 관련 설정(ignore_index)은 할 필요 X
pd.concat((pd.read_csv(file) for file in oil_files),axis='columns').head()
6> 완성!

- glob, concat으로 끝 👍 -

댓글