① case 1
# Define the model
model = tf.keras.models.Sequential([
# Add convolutions and max pooling
tf.keras.layers.Conv2D(32, (3,3), activation='relu', input_shape=(28, 28, 1)),
tf.keras.layers.MaxPooling2D(2, 2),
tf.keras.layers.Conv2D(32, (3,3), activation='relu'),
tf.keras.layers.MaxPooling2D(2,2),
# Add the same layers as before
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(128, activation='relu'),
tf.keras.layers.Dense(10, activation='softmax')
])
(1) tf.keras.layers.Conv2D(32, (3,3), activation='relu', input_shape=(28, 28, 1))

① input으로 넣은 건 가로 28 x 세로 28 pixel의 2d image이고, 해당 image는 grayscale이므로 input shape은 (28,28,1)
② 3x3 크기의 convolution filter가 (28,28,1) shape input에 적용됨. 그 결과 한 개의 filter 당 (26,26,1) output 산출
③ 총 32개의 다른 convolution filter가 각각 (28,28,1)에 적용되므로 최종 output은 (26,26,1)이 32개 모인 (26,26,32)
④ 사용된 parameter는 convolution filter 1개에 (3x3 + 1)인 10개 적용. (이 때 1은 모든 filter마다 존재하는 bias term) 총 32개의 filter이므로 10 x 32인 320개가 첫 컨볼루션 단계에서 사용된 paramter 개수
(2) tf.keras.layers.MaxPooling2D(2,2)
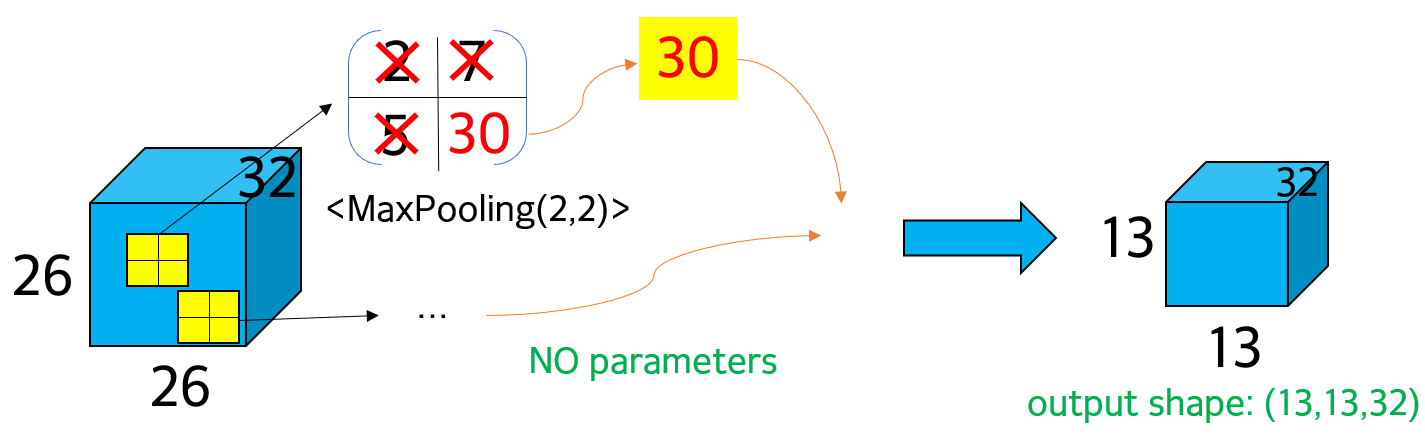
① maxpooling(2,2)으로 가로와 세로 size 각각 절반으로 줄인다. max pooling이므로 4개의 pixel 중 최댓값만 선택하고 나머지 ignore
② 가로와 세로 size 각각 절반으로 줄었으므로 output shape은 (13,13,32). depth는 유지
③ pooling에서 사용된 parameter는 없음
(3) tf.keras.layers.Conv2D(32, (3,3), activation = 'relu')
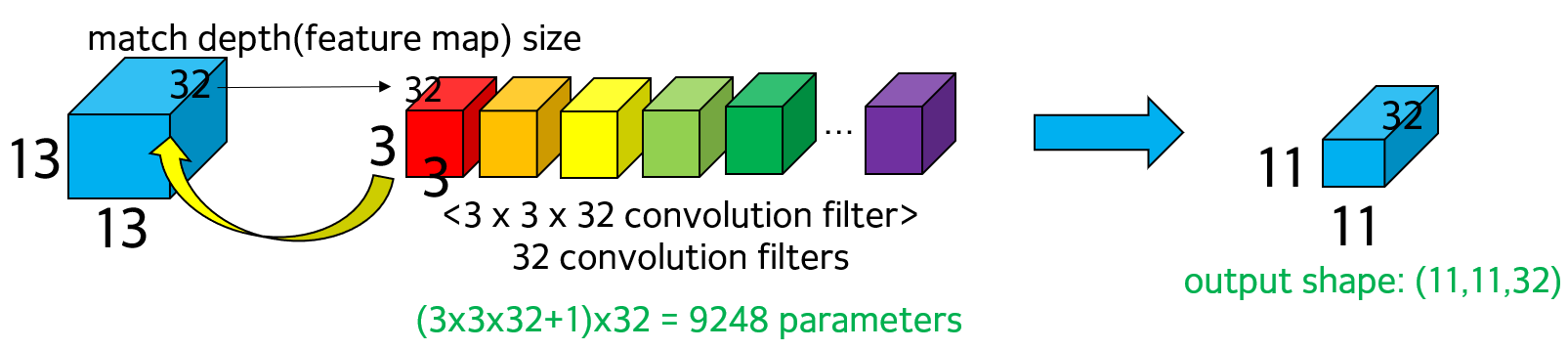
① input shape이 (13,13,32)이므로 depth가 32. 따라서 convolution filter의 size는 3x3x1이 아닌 depth에 맞춰서 3x3x32로 바뀜. 똑같은 3x3 convolution filter 내용이 총 32개의 depth에 각각 적용되어야 하므로 replicated 32 times
② 즉 3x3 convolution filter가 첫 feature map 13x13에 적용. 동일한 filter가 두번째 feature map 13x13에 적용 ~ 총 32번 적용. 32번 적용된 결과를 aggregate해서 11x11x1의 결과로 산출
③ 총 32개의 다른 convolution filter가 존재하므로 output shape은 11x11x32
④ 사용된 parameter는 각 convolution filter에서 (3x3x32+1) 개수. 해당 convolution filter는 32개 있으므로 (3x3x32+1)x32 따라서 9248개
(4) tf.keras.layers.MaxPooling2D(2,2)
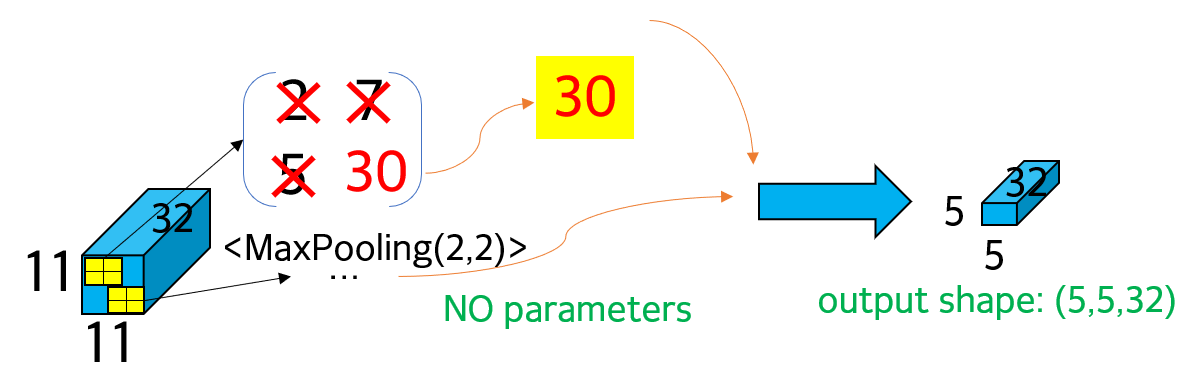
① 과정 (2) 와 동일하게 max pooling 진행. maxpooling(2,2)이므로 가로와 세로 size 각각 절반으로 줄임. 다만, input size가 (11,11,32)로 odd length이기 때문에 일부 파트는 max pooling에서 무시됨. 만약, 무시되지 않을 정도로 중요한 정보로 간주해야 한다면 max pooling 이전 단계에 padding을 적용.
② 따라서 truncated된 (5,5)로 size가 절반 이하로 줄었고, depth는 유지되므로 최종 output shape은 (5,5,32)
③ max pooling 단계에서 사용된 파라미터는 없음
(5) tf.keras.layers.Flatten()

① 5x5x32로 총 800개의 숫자가 존재하고 이후 fully-connected layers로의 계산을 위해 800개의 데이터로 구성된 한 층으로 flattening
(6) tf.keras.layers.Dense(128, activation='relu') / (7) tf.keras.layers.Dense(10, activation='softmax')
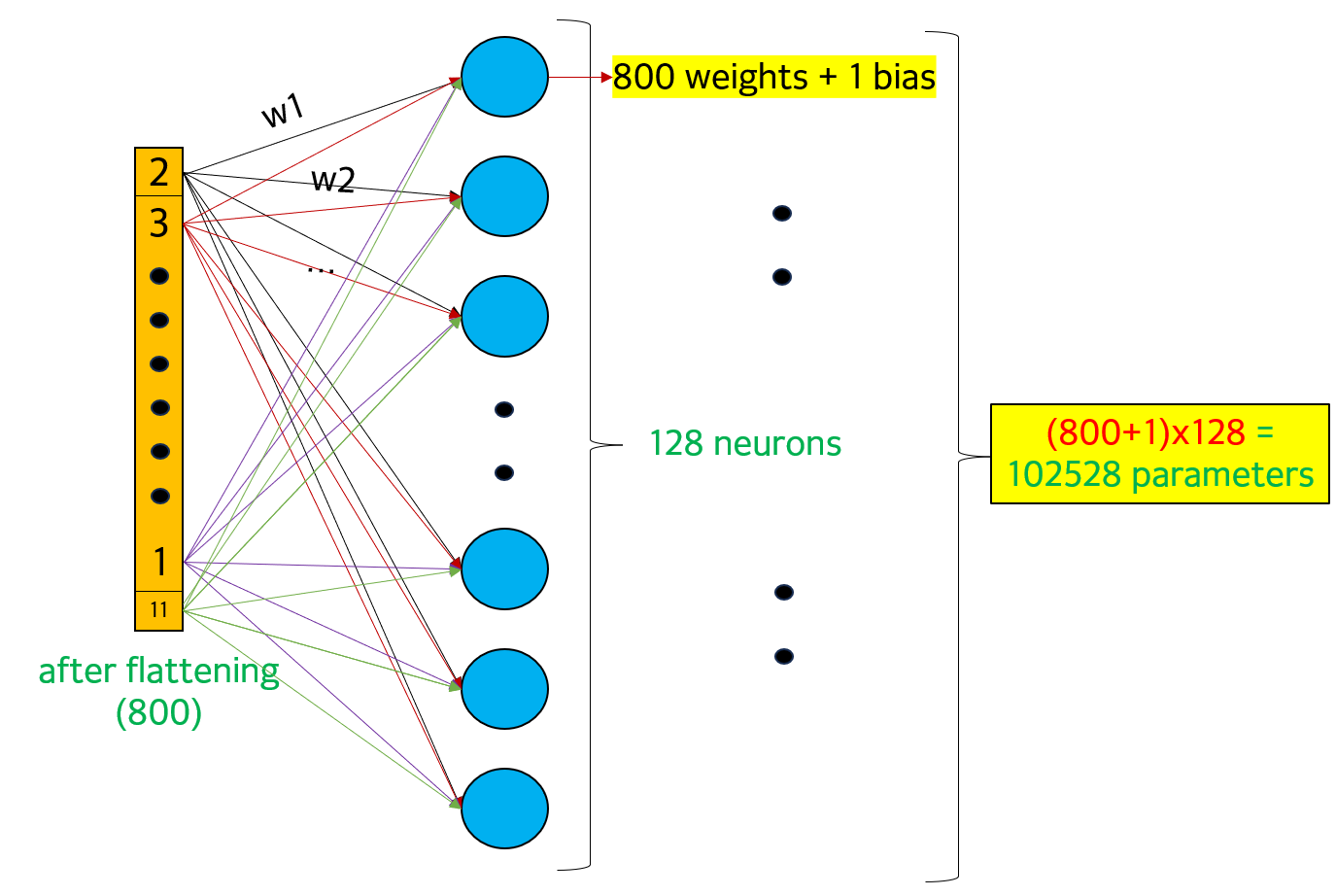

① Dense layer는 128개의 neuron으로 구성되어 있고, ReLU activation을 갖고 있다고 만들어져 있다. 이 때 각 neuron은 flattening 결과의 모든 800개 데이터와 연결(fully-connected)되어 있다. 각 connection은 각각의 고유한 weight parameter를 1개씩 갖고 있으므로, 각 neuron에는 총 연결된 connection 개수만큼(800개) parameter 존재
② 각 neuron에 추가로 bias parameter가 1개씩 있으므로 각 neuron에는 합계 801개 parameter 존재. 따라서 최종 parameter 개수는 801*128로 102528 개수만큼 들어있다.
③ 그 다음 한 번 더 Dense layer를 거치고, 첫번째 Dense layer의 결과인 128 neuron이 10개의 neuron으로 거친다. 따라서 각 neuron당 역시 fully-connected 되어 있어 총 128개의 weight과 bias 1개 합쳐서 129개의 paramter를 갖고 있으므로 최종 parameter 개수는 (128+1)*10으로 1290 개의 paramter 존재
※ activation 작동 과정
: 먼저 각 neuron당 input으로부터 corresponding weight만큼 곱해진 결과가 합해진다. 그 다음 bias term을 고려해서 최종 summed weight이 각 neuron마다 나오고, ReLU 또는 softmax등 activation 함수가 적용(element-wise)되어 각 neuron당 최종 output이 나온다. (자세한 건 이후 포스팅 참조)
② case 2
# Define the model
model = tf.keras.models.Sequential([
# Add convolutions
tf.keras.layers.Conv2D(1, (3,3), activation='sigmoid', input_shape=(10, 10, 1)),
])
: input_shape이 (10,10,1)이므로 grayscale된 10x10 size의 image. 3x3 size의 Convolution filter 1개가 해당 image에 적용된다. 그 결과 output shape은 (8,8,1) (1개의 convolution filter만 존재하므로 depth는 1). 사용된 parameter는 convolution filter (3x3+1(bias))로 총 10개
③ case 3
# Define the model
model = tf.keras.models.Sequential([
# Add convolutions
tf.keras.layers.Conv2D(5, (3,3), activation='sigmoid', input_shape=(10, 10, 1)),
tf.keras.layers.Conv2D(2, (3,3), activation='sigmoid')
])
(1) input shape 동일. 3x3 Convolution filter가 다만 1개가 아니라 5개. 따라서 output shape 결과는 (8,8,5). 각 convolution filter(서로 다른)가 각각의 image에 적용된 후의 결과가 5개 모였으므로 (8,8,5)이다. 사용된 parameter는 convolution filter(3x3+1)가 5개이므로 (3x3+1)x5로 50개.
(2) 이후 (8,8,5) output에 (3,3) size Convolution filter 2개를 적용한다. 이 때 (3,3) Convolution filter가 (8,8,5)에 적용되어야 하므로 (3,3,5)로 size를 늘린 뒤(replicated) 5번 적용. 5번 적용된 결과를 aggregate해서 (6,6,1) size 생성. 해당 Convolution filter가 2개 있으므로 최종 output size는 (6,6,2). 사용된 parameter는 convolution filter(3x3x5+1)가 2개 있으므로 총 92개. 이 때 replicated되어서 convolution filter의 depth가 1에서 5로 됨에 주의하자
④ case 4
# Define the model
model = tf.keras.models.Sequential([
# Add convolutions
tf.keras.layers.Conv1D(8, 3, activation='sigmoid', input_shape=(100,5)),
tf.keras.layers.Conv1D(1, 3, activation='sigmoid')
])
↑ 1D Convolution filter도 적용할 수 있다.
(1) 100 size의 2차원 data(tabular data) (channel: 5)가 input으로 존재. size 3인 convolution 1차원 filter 8개가 적용된다. channel, 즉 depth가 5이므로 convolution filter는 (3,5)로 replicated. 해당 convolution filter가 적용된 후의 size는 98. 이 때 replicated된 5개가 aggregate되어서 1개로 됨. 따라서 (98,1). 이 때 filter가 8개 이므로 output shape은 (98,8). parameter 개수는 한 개의 convolution filter는 (3x5+1). 따라서 총 128개의 paramter 생성 (3x5+1)x8
(2) 그 다음 단계에 동일한 size 3의 Convolution 1D filter 1개가 (98,8)에 적용된다. Convolution은 (3,8)로 replicate되어 적용되고, aggregate되어 1개로 산출해 최종 output은 (96,1). 사용된 parameter 개수는 (3x8+1)x1로 총 25개 parameter.
chatgpt
'Deep Learning > Fundamentals' 카테고리의 다른 글
| C1W2 - Logistic Regression as a Neural Network (0) | 2023.09.06 |
|---|

댓글