0003. Longest Substring Without Repeating Characters / 0221. Maximal Square


#---------------- (1)
class Solution:
def lengthOfLongestSubstring(self, s: str) -> int:
ans = 0
hashmap = dict()
for i in range(len(s)):
if s[i] in hashmap.keys():
needs_to_be_deleted_keys = set()
for key in hashmap:
if hashmap[key] < hashmap[s[i]] and key != s[i]:
needs_to_be_deleted_keys.add(key)
hashmap[s[i]] = i
for key in needs_to_be_deleted_keys:
del hashmap[key]
else:
hashmap[s[i]] = i
ans = max(ans,len(hashmap))
return ans
#----------------- (2)
class Solution:
def lengthOfLongestSubstring(self, s: str) -> int:
ans = 0
window = ''
for i in range(len(s)):
if s[i] in window:
end = window.find(s[i])
window = window[end+1:]
window+=s[i]
ans = max(ans,len(window))
return ans
#-------------------- (3)
class Solution:
def lengthOfLongestSubstring(self, s: str) -> int:
charSet = set()
l = 0
res = 0
for r in range(len(s)):
while s[r] in charSet:
charSet.remove(s[l])
l+=1
charSet.add(s[r])
res = max(res, r-l+1)
return resclass Solution:
def maximalSquare(self, matrix: List[List[str]]) -> int:
for row in range(len(matrix)):
for col in range(len(matrix[0])):
matrix[row][col] = int(matrix[row][col])
col, row = len(matrix), len(matrix[0])
dp = [[-1]*row for _ in range(col)]
x,y=col-1,row-1
while x>=0 and y>=0:
#(x,y) -> (x,0)
for r in range(y,-1,-1):
if x == (col-1):
dp[x][r] = matrix[x][r]
else:
if matrix[x][r] == 0:
dp[x][r] = 0
else:
dp[x][r] = (int(min(dp[x][r+1],dp[x+1][r],dp[x+1][r+1])**(1/2))+1)**2
#(x-1,y) -> (0,y)
for c in range(x-1,-1,-1):
if y == (row-1):
dp[c][y] = matrix[c][y]
else:
if matrix[c][y] == 0:
dp[c][y] = 0
else:
dp[c][y] = (int(min(dp[c][y+1],dp[c+1][y],dp[c+1][y+1])**(1/2))+1)**2
x-=1
y-=1
return max(max(row) for row in dp)
🧑🏻💻 0003)
☆ slding window로 겹치는 문자열이 없게끔 O(n)으로 window sliding 진행. 이 때 동일 문자가 등장한다면, 기존 문자열에서 처음부터 동일 문자포함 substring 제거 / sliding 하면서 sliding window 길이 최댓값을 리턴

☆ (위 코드는 hahsmap을 이용한 풀이 / 아래 코드는 window 문자열 이용한 풀이)
☆ 아니면 위 코드 세번째 풀이로 직접 window 업데이트 보다는, window 맨 앞과 맨 뒤의 l, r 포인터를 잡아서 O(N)으로 돌려 length를 l-r+1로 업데이트. 그리고, window 안의 동일 문자 만날 때까지만 l을 업뎃하고 / charSet으로 set() 자료구조를 사용해 제일 시간 복잡도 상 효율적인 코드
🧑🏻💻 0221)
☆ 전형적인 dp 문제(2차원 dp로, 오른쪽 아래부터 왼쪽 위까지 업데이트 되는 문제)
☆ 1로만 구성된 '정사각형'의 최대 넓이 구하기
→ (x,y)가 왼쪽 끝인 정사각형(x, y 모두 index 0기준) 이 있다면 dp[x][y] 는 (x,y)를 왼쪽 끝으로 가지는 정사각형 중 최대 넓이
→ 그러면 오른쪽 아래부터 시작해 row 방향 왼쪽으로 / col 방향 위쪽으로 업데이트 하면서 최대 넓이 업데이트
→ dp[x][y] = (dp[x+1][y], dp[x][y+1], dp[x+1][y+1] 중 최솟값의 root + 1)을 제곱한 결과

0394. Decode String / 0022. Generate Parentheses


class Solution:
def decodeString(self, s: str) -> str:
stack = []
ans = ''
for x in s:
if x == ']':
to_be_repeated=''
while stack:
end = stack[-1]
if end.isalpha():
for alpha in end[::-1]:
to_be_repeated+=alpha
stack.pop()
elif end=='[':
stack.pop()
else: #digit
repeat_number = ''
while stack and stack[-1].isdigit():
repeat_number+=stack.pop()
stack.append(to_be_repeated[::-1]*int(repeat_number[::-1]))
break
else:
stack.append(x)
return ''.join(stack)class Solution:
def generateParenthesis(self, n: int) -> List[str]:
def track(parentheses, closed_nums, opened_nums):
if closed_nums == opened_nums == 0: #track finished
ans.append(''.join(parentheses))
return
if opened_nums == 0:
parentheses.append(')') #add closed
track(parentheses, closed_nums-1, opened_nums)
parentheses.pop()
elif closed_nums > opened_nums:
parentheses.append(')') #add closed
track(parentheses, closed_nums-1, opened_nums)
parentheses.pop()
parentheses.append('(') #add opened
track(parentheses, closed_nums, opened_nums-1)
parentheses.pop()
else: #closed_nums == opened_nums
parentheses.append('(') #add opened
track(parentheses, closed_nums, opened_nums-1)
parentheses.pop()
closed_nums, opened_nums = n, n-1
parentheses = ['(']
ans = []
track(parentheses, closed_nums, opened_nums)
return ans
🧑🏻💻 0394)
☆ stack에 계속 넣다가 ]를 만나면 [를 만나기 전까지 반복할 문자 to_be_repeated에 저장. 이 때, 'a', 'bcd'를 만나면 'abcd'로 바꾸어야 하므로 stack 구조 상 맨 오른쪽 문자부터 빼기 때문에 bcda가 된다. 하지만, dcba가 되어야 하기에 뺄 때 [::-1]에서 각 문자를 빼 dcba로 만들어서 저장
(반례: stack에 'a', 'bcd'이렇게 알파벳이 뭉쳐서 들어갈 때 주의)
☆ [를 만나면 pop()
☆ digit을 만나면, 반복하고자 하는 횟수이므로, 이 때 숫자의 길이가 2 이상일 수 있으므로 숫자가 아닐 때까지 pop()을 진행해 숫자문자를 모아 repeat_number로 만든 다음 [::-1]을 해 int()로 바꾸고 to_be_repeated를 반복
(반례: stack에 단일 숫자가 아닌 두 자리 이상의 숫자, 예를 들어 100이 '1', '0', '0' 이렇게 들어가 있을 때 100이라는 숫자로 만들기 주의)
🧑🏻💻 0022) 매우 교육적인 backtracking 문제
☆ 일단 well-formed parentheses를 채워나가는 과정을 보자. (를 opened, )를 closed라고 하면 왼쪽부터 parentheses를 채워나가면서 closed 변수는 opened 변수를 초과할 수 없다.
ex) ()와 같이 opened과 closed가 동일한 경우 / (()와 같이 opened > closed인 경우 이렇게 2가지 케이스가 있다. 하지만, ())와 같이 closed가 opened를 앞서 나가서 괄호를 만든 경우는 없다.
☆ 그렇다면, 앞서 만들어진 진행 중인 parentheses는 closed == opened, opened > closed인 2가지 케이스만 있다.
(1) opened == closed인 경우, (())와 같이 그 다음 오른쪽엔 (만 추가할 수 있다. (else문 마지막 세번째)
(2) opened > closed인 경우, (()와 같이 그 다음 오른쪽엔 (와 ) 모두 추가할 수 있다. (elif문 두번째 조건)
(다만, 코드에선 남은 개수이므로 closed < opened 조건이다)
※ 다만, 그 전에 opened가 closed 보다 먼저 순위가 앞서므로 opened == 0일 수 있다. 이 때는 closed ) 만 추가할 수 있다.(if문 첫번째 조건)
☆ track() 함수 return문) 당연히 남은 closed 개수와 opened 개수가 모두 0일 때, ans에 업데이트하고 return.
0215. Kth Largest Element in an Array / 0128. Longest Consecutive Sequence


class Solution:
def findKthLargest(self, nums: List[int], k: int) -> int:
freq = Counter(nums)
sorted_freq = sorted(freq.items(), key=lambda x: x[0], reverse = True)
# print(sorted_freq)
for pair in sorted_freq:
k -= pair[1]
if k <= 0:
return pair[0]class Solution:
def longestConsecutive(self, nums: List[int]) -> int:
if not nums:
return 0
#nums = list(set(nums))
nums.sort()
ans, cur = 0, 0
for x in range(len(nums)):
if x == 0:
ans = 1
cur += 1
else:
if nums[x] == nums[x-1]:
continue
if nums[x] - 1 == nums[x-1]:
cur += 1
ans = max(ans,cur)
else:
cur = 1
return ans
🧑🏻💻 0215) 중복해서 포함된 숫자 리스트 중 k번째 큰 원소 구하기. 각 원소의 frequency가 들어간(counter 사용) dictonary에서, sorted 진행 후, k에 value frequency 빼면서 음수이거나 0일 때 해당되는 key k값을 출력
🧑🏻💻 0128)
(1) 일단 sort()로 정렬(O(nlogn))
(2) 첫번째 원소일 때 ans = 1, cur = 1로 초기화
(3) for문 이후 진행하면서
① 앞의 원소와 같을 때는 ans와 cur 업데이트 없이 바로 continue
② 앞의 원소와 같지 않을 때,
- 앞의 원소 + 1이 현재 원소와 같다면 누적 cur += 1하고, 업데이트한 cur과 현재의 ans 비교하면서 최댓값으로 ans update
- 앞의 원소 + 1이 현재 원소와 같지 않다면 누적 cur = 1 초기화
(4) 최종 ans return
0091. Decode Ways / 0437. Path Sum III


class Solution:
def numDecodings(self, s: str) -> int:
hashMap = dict()
number = 1
for alphabet in 'ABCDEFGHIJKLMNOPQRSTUVWXYZ':
hashMap[str(number)] = alphabet
number+=1
dp = []
for i in range(len(s)):
l = 0
if i == 0:
if s[i] in hashMap.keys():
l+=1
else:
if s[i-1:i+1] in hashMap.keys(): #check double
if i%2==0:
l+=dp[0]
else:
if i == 1:
l+=1
else:
l+=dp[1]
if s[i] in hashMap.keys(): #check one letter
if i%2==0:
l+=dp[1]
else:
l+=dp[0]
if i == 0 or i == 1:
dp.append(l)
else:
if i%2==0:
dp[0] = l
else:
dp[1] = l
length = len(s)
if length%2==0:
return dp[1]
else:
return dp[0]# Definition for a binary tree node.
# class TreeNode:
# def __init__(self, val=0, left=None, right=None):
# self.val = val
# self.left = left
# self.right = right
class Solution:
def pathSum(self, root: Optional[TreeNode], targetSum: int) -> int:
def dfs(root, ps):
if not root:
return #stop
cs = ps + root.val
x = cs - targetSum
if x in freq:
self.count += freq[x]
if cs in freq:
freq[cs] += 1
else:
freq[cs] = 1
dfs(root.left, cs)
dfs(root.right, cs)
freq[cs]-=1
self.count = 0
freq = {0:1}
dfs(root, 0)
return self.count
🧑🏻💻 0091) dp 미디엄 난이도 문제. 11106이라는 숫자 문자열이 있다면, 1 - 11 - 111 - 1110 - 11106 이렇게 업데이트 하는 dp 형식으로 문제를 해결할 수 있다. dp는 주어진 알파벳 개수로 만들 수 있는 경우의 수이다.
+ 먼저 key 숫자에 따른 value HashMap을 만든다.
(1) 첫 1일 때: 현재 숫자 '1'로 만들 수 있는 알파벳 경우의 수 1가지(A)
(2) 두번째 1일 때: 앞선 숫자 '1'로 만들 수 있는 경우의 수(거기에 '1'을 붙인 것이므로 AA 1가지) / '11' 자체로 만들 수 있는 경우(K 1가지): 총 2가지
(3) 세번째 1일 때: 앞선 (2) 케이스에서 '1'인 A를 붙인 경우(즉, AAA, KA) / 그리고 앞선 (1) 케이스에서 '11'인 K를 붙인 경우(AK): 총 3가지
(4) 네번째 0일 때: 앞선 (3) 케이스에서 '0'을 붙이는 건 x('0' 자체가 없으므로) / 그리고 앞선 (2) 케이스에서 '10'인 'J'를 붙인 경우(AAJ, KJ): 총 2가지
(5) 다섯번째 6일 때: 앞선 (4) 케이스에서 '6'인 F를 붙인 경우(AAJF, KJF) / 앞선 (3) 케이스에서 '06'을 붙이는 건 x('06' 자체가 없으므로): 총 2가지
∴ 따라서 총 2가 출력된다.
++ 추가로 메모리 절약을 위해 위 예시에서 (5) 경우의 수를 구할려면 (3)과 (4) 케이스만 알면 되므로 dp size는 2로만 설정해도 충분. 다만, index i의 홀짝 여부에 따라 다르게 업데이트.
+ i = 0 첫번째 숫자일 때(숫자 1개 자체만 확인)
++ i > 0 두번째 숫자이상일 때 (숫자 1개 자체 + 앞선 케이스까지 같이 확인)
🧑🏻💻 0437)
** 위 root를 반드시 시작하지 않아도 일부 부분 경로 내의 합이 targetSum과 같다면 해당 경로도 답으로 카운트.
** 이 때, dfs 방식으로 우리는 위부터 아래 leaf node 방향까지 아래 tree의 경우 총 4개의 route가 나온다고 할 수 있다.
(1) root node를 start node로 하고, leaf node를 terminal node로 한 4개의 경로 case

(2) 첫번째 경로 10 - 5 - 3 - 3 경로에서 targetSum이 8이 되는 부분 route가 있는 지 확인해보자
* freq dictionary 활용.
* 10 → 5 → 3 → 3 으로 진행하면서 freq dictionary {10: 1} {10 : 1, 15: 1} {10 : 1, 15 : 1, 18 : 1} {10 : 1, 15 : 1, 18 : 1, 21 : 1}로 계속 업데이트.
ex) 10 → 5 → 3 까지 갔을 때의 경로를 확인. cs는 18. 그렇다면 targetSum은 8이므로, x = cs - targetSum = 18 - 8 = 10이 된다. 그러면 10이 freq에 key로 존재하는 지 확인.

: 10이 freq.keys()에 존재한다면, freq[10]에 해당되는 10이 누적합인 frequency를 더해준다.
(3) dfs안에 dfs 재귀로 끝난 후, 다시 이전 상태로 돌아가는, tree에서 아래 노드에서 상위 노드로 올라가므로, 직접 freq[cs] -= 1로 freq 이전 상태로 되돌아감.
0061. Rotate List / 0143. Reorder List


# Definition for singly-linked list.
# class ListNode:
# def __init__(self, val=0, next=None):
# self.val = val
# self.next = next
class Solution:
def rotateRight(self, head: Optional[ListNode], k: int) -> Optional[ListNode]:
if not head:
return head
#get length
length, tail = 1, head
while tail.next:
tail = tail.next
length += 1
k = k%length
if k == 0:
return head
cur = head
for i in range(length - k - 1):
cur = cur.next
newHead = cur.next
cur.next = None
tail.next = head
return newHead# Definition for singly-linked list.
# class ListNode:
# def __init__(self, val=0, next=None):
# self.val = val
# self.next = next
class Solution:
def reorderList(self, head: Optional[ListNode]) -> None:
"""
Do not return anything, modify head in-place instead.
"""
#find middle
slow, fast = head, head.next
while fast and fast.next:
slow = slow.next
fast = fast.next.next
#reverse second half
second = slow.next
slow.next = None
prev = None
while second:
tmp = second.next
second.next = prev
prev = second
second = tmp
#merge two linked lists
first = head
while first and prev:
tmp1 = first.next
tmp2 = prev.next
first.next = prev
prev.next = tmp1
first = tmp1
prev = tmp2
return head
🧑🏻💻 0061)
(1) 먼저 length를 구해서 k = k%length로 맨 오른쪽 tail node가 몇 번 앞으로 이동하는 지 k 값을 구한다.
(2) k == 0이면 이동하지 않는 것이므로 return head
(3) k번 이동한 건, 결국은 뒤 오른쪽 기준 k개의 node가 앞 쪽으로 이동, 그렇다면 length - k개의 node가 뒤 쪽으로 이동한 것 과 같다. 아래 그림 참조
(k = 3일 때 2개의 node 묶음 1 - 2가 뒤 오른쪽 기준 3개의 node 묶음 3 - 4 - 5 뒤쪽으로 이동)

: idea)
그렇다면, head를 length - k - 1번 이동해서 앞 length - k개 node 묶음의 맨 끝 쪽으로 이동(cur).
cur.next를 newHead로 해서, newHead를 head로 새롭게 만들고, 맨 끝 쪽 tail.next = head로 선 이어주기(위 그림에서는 5 - 1). 그 다음 cur.next = None으로 2와 3 사이의 선 끊기. (아래 그림 참조)

🧑🏻💻 0143)
ex) 1 - 2 - 3 - 4 - 5 - 6 이렇게 구성된 linked list가 있다면 1 - 6 - 2 - 5 - 3 - 4 이렇게 구성. 먼저 1 - 2 - 3 / 4 - 5 - 6 이렇게 절반으로 나누고, 절반으로 나눈 두 번째 리스트를 reverse 한다. 즉, 1 - 2 - 3 / 6 - 5 - 4 이렇게 만든다. 그 다음, 1은 6으로 연결, 6은 2로 연결로 지그재그 연결을 진행함으로써 최종적으로 원하는 1 - 6 - 2 - 5 - 3 - 4 이렇게 만들어 낼 수 있다.
(1) 1 - 2 - 3 - 4 - 5 - 6을 1 - 2- 3 / 4 - 5 - 6 이렇게 절반으로 리스트 두 개로 나누기
(1) - 1: 먼저 slow, fast pointer를 사용해 slow pointer가 리스트의 절반 위치에 오게 한다. (slow pointer 구하기)
(노드 개수가 홀수라면 정확하게 중간 노드에 slow pointer / 노드 개수가 짝수라면 중간 바로 앞 노드에 slow pointer)

#find middle
slow, fast = head, head.next
while fast and fast.next:
slow = slow.next
fast = fast.next.next
(1) - 2: head부터 slow까지 첫번째 linked list / 그리고 slow 다음부터 끝까지 두번째 linked list로 만들기. 즉, slow와 slow 다음 노드 사이의 줄을 없애야 한다. 일단, 잘리는 오른쪽 linked list의 맨 왼쪽 node는 second로 / slow.next = None으로 설정. .next = None으로 설정하면 자동적으로 줄이 사라진다.

second = slow.next
slow.next = None
(2) 오른쪽 linked list를 reverse 하기
(2): 주어진 linked list를 reverse하기 위해서는 prev = None을 미리 만들어 놓고, 현재 포인터 second가 그 앞의 node prev를 가리키게 계속 진행해 주면 된다. 이 때, 도중에 linked list가 끊기면 안되므로 (1) second.next인 second 오른쪽 node를 tmp로 먼저 설정. 그 다음 (2) second.next = prev로 줄 reverse. (3)(4) 그 다음 prev와 second update

prev = None
while second:
tmp = second.next
second.next = prev
prev = second
second = tmp
(3) 두 linked list를 merge하기
: first와 prev 맨 앞 노드에 포인터로 있는 상태에서 head가 prev로 연결, prev가 first.next로 연결되는 두 화살표 조정 과정을 반복적으로 거치면 merging 완료! (1) first와 prev 둘 다 있는 상태에서 while문 돌리고 (2) first.next와 prev.next 각각 tmp1, tmp2 미리 저장 (3) 그 다음 first.next = prev, prev.next = tmp1으로 화살표 2개 재조정 (4) first와 prev tmp1과 tmp2로 각각 업데이트
: 최종적으로 return head

0073. Set Matrix Zeroes / 0148. Sort List


class Solution:
def setZeroes(self, matrix: List[List[int]]) -> None:
"""
Do not return anything, modify matrix in-place instead.
"""
visited = [[False]*len(matrix[0]) for _ in range(len(matrix))]
for row_i in range(len(matrix)):
for col_i in range(len(matrix[0])):
if matrix[row_i][col_i] == 0 and not visited[row_i][col_i]:
for i in range(len(matrix[0])):
if matrix[row_i][i] == 0 and not visited[row_i][i]:
continue
matrix[row_i][i] = 0
visited[row_i][i] = True
for j in range(len(matrix)):
if matrix[j][col_i] == 0 and not visited[j][col_i]:
continue
matrix[j][col_i] = 0
visited[j][col_i] = True
🧑🏻💻 0073)
* 0을 발견했을 때, 해당 칸을 포함한 행과 열에 모두 zero out을 해줘야 하지만, 그로 인해 새롭게 만들어진 zero는 기존 zero와 다르다는 걸 명심.
* 따라서, visited 2차원 배열을 활용해, not visited이면서 zero out될 곳이 이미 0이면서 not visited한 곳이면 당연히 0 만들지 말고 visited False 처리. 즉, visited된 0은 새롭게 만들어진 zero이므로, visited가 안된 0과 visited 유무로 구별할 수 있다.
# Definition for singly-linked list.
# class ListNode:
# def __init__(self, val=0, next=None):
# self.val = val
# self.next = next
class Solution:
def sortList(self, head: Optional[ListNode]) -> Optional[ListNode]:
if not head or not head.next:
return head
#split the list into two halves
left = head
right = self.getMid(head)
tmp = right.next
right.next = None
right = tmp
left = self.sortList(left)
right = self.sortList(right)
return self.merge(left, right)
def getMid(self, head):
slow, fast = head, head.next
while fast and fast.next:
slow = slow.next
fast = fast.next.next
return slow
def merge(self, left, right):
tail = dummy = ListNode()
while left and right:
if left.val < right.val:
tail.next = left
left = left.next
else:
tail.next = right
right = right.next
tail = tail.next
#add the remaining elements
if left:
tail.next = left
if right:
tail.next = right
return dummy.next
🧑🏻💻 0148) O(nlogn) merge sort 진행
* merge sort는 먼저 주어진 list를 재귀적으로 두 list로 나누고, 다시 올라오면서 merging 하는 과정을 반복한다(별도 merge sort 포스팅 참조)
* merge sort 아래 그림 참조
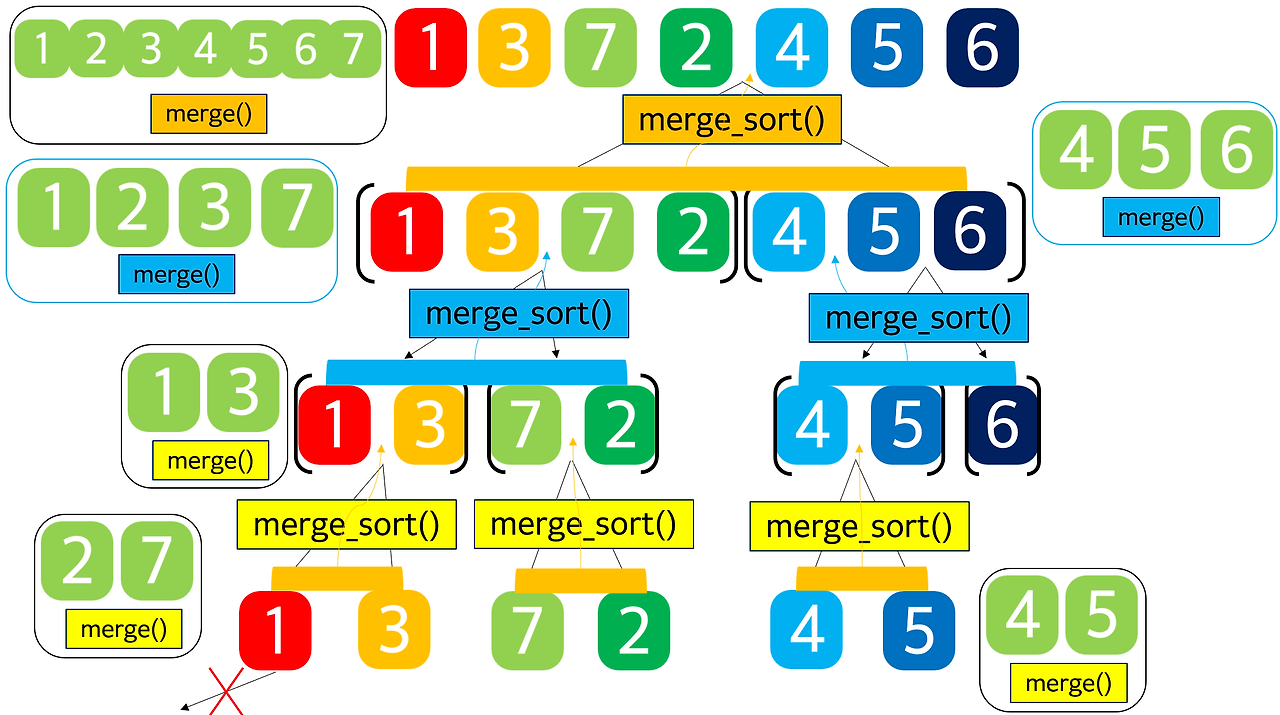
(1) list의 node 개수가 0이거나 1일 때 return head
(2) list를 2개(left, right)로 나누기
#split the list into two halves
left = head
right = self.getMid(head)
tmp = right.next
right.next = None
right = tmp
: getMid()의 결과, 노드의 개수가 짝수일 경우 right는 바로 앞 node. 따라서 right.next로 오른쪽 array의 맨 앞 node tmp로 설정 뒤, right.next = None으로 한 개의 linked list를 두 개의 linked list로 자르기. tmp로 임시 설정한 포인터 위치에 right 넣기. 최종 결과 left를 포인터로 가지는 왼쪽 array와 right를 포인터로 가지는 오른쪽 array 2개 생성.
(3) 재귀적으로 left와 right 각각 나누고, 재귀 이후 내용(즉, backtracking상 위로 올라오는)은 merging 단계(두 list sorting하며 합치는) 진행
left = self.sortList(left)
right = self.sortList(right)
return self.merge(left, right)
(4) getMid(self, head)
: head로 주어진 array의 절반을 나누기. linked list에서 두 조각으로 쪼개려면 fast와 slow pointer 사용. 최종적으로 update된 slow pointer 리턴
(5) merge(self, left, right)
: 두 list를 합치는 과정에서 sorting 진행. 두 list 각각 맨 앞의 pointer left, right라고 하자. 아래와 같은 방식으로 sorting 진행.

def merge(self, left, right):
tail = dummy = ListNode()
while left and right:
if left.val < right.val:
tail.next = left
left = left.next
else:
tail.next = right
right = right.next
tail = tail.next
#add the remaining elements
if left:
tail.next = left
if right:
tail.next = right
return dummy.next
: 가상의 dummy node 만들어 놓고, left와 right 각각의 value 비교하면서 작은 것 먼저 붙이기. left와 right 중 둘 중 적어도 하나 traversing 다 끝났다면, 만약에 이후 left 또는 right 쪽에 남은 원소가 있다면 left나 right를 붙이기. 최종적으로 dummy 그 다음 node로 sorting 된 것 확인 가능.
0048. Rotate Image / 0380. Insert Delete GetRandom O(1)


class Solution:
def rotate(self, matrix: List[List[int]]) -> None:
"""
Do not return anything, modify matrix in-place instead.
"""
n = len(matrix)
# Transpose the matrix
for i in range(n):
for j in range(i, n):
matrix[i][j], matrix[j][i] = matrix[j][i], matrix[i][j]
# Reverse each row
for row in matrix:
row.reverse()
🧑🏻💻 0048) 시계방향으로 90도 회전은 transpose(왼쪽 대각선 기준 값 서로 바꿈) → 그리고 각 row reverse 두 단계를 뜻함.
class RandomizedSet:
def __init__(self):
self.numMap = {}
self.numList = []
def insert(self, val: int) -> bool:
res = val not in self.numMap
if res:
self.numMap[val] = len(self.numList)
self.numList.append(val)
return res
def remove(self, val: int) -> bool:
res = val in self.numMap
if res:
idx = self.numMap[val]
lastVal = self.numList[-1]
self.numList[idx] = lastVal
self.numList.pop()
self.numMap[lastVal] = idx
del self.numMap[val]
return res
def getRandom(self) -> int:
return random.choice(self.numList)
# Your RandomizedSet object will be instantiated and called as such:
# obj = RandomizedSet()
# param_1 = obj.insert(val)
# param_2 = obj.remove(val)
# param_3 = obj.getRandom()
🧑🏻💻 0380) 원하는 숫자를 insert하는 건 쉽게 O(1)로 list에 append 가능. 하지만, 원하는 숫자가 list에 존재한다면, remove() 연산을 활용해 지우는 건 O(1) 불가능. 이 때, hashMap을 활용해, 지우고자 하는 원소의 index를 O(1)로 확인하고, 그 index를 idx라고 한다면, list의 해당 idx 자리에 list 맨 오른쪽 원소를 넣으면 된다. 단순히 del list_이름[idx] operation으로 진행할 수 있지만, 그렇다면, 해당 idx+1부터 list 오른쪽 끝까지 모든 원소의 index를 update해야 하기에 O(N). 따라서, list의 맨 오른쪽 원소를 idx 자리로 넣는 idea가 필요! 아래 그림 참조

: [3, 1, 5, 2, 4]에서 중간 원소 5를 O(1)로 remove하는 방법
→ 5의 index 2에 해당하는 자리에 맨 오른쪽 원소 4를 넣는다(O(1)). 그리고 맨 오른쪽 4를 pop(O(1))으로 지운다. 그리고 hashMap update와 deletion O(1)로 진행.
0210. Course Schedule II / 0253. Meeting Rooms II


class Solution:
def findOrder(self, numCourses: int, prerequisites: List[List[int]]) -> List[int]:
ans = []
indegrees = [0]*(numCourses)
graph = [[] for _ in range(numCourses)]
for order in prerequisites:
a,b=order[0],order[1]
graph[b].append(a)
indegrees[a]+=1
queue = deque()
for n in range(len(indegrees)):
if indegrees[n] == 0:
queue.append(n)
while queue:
node = queue.popleft()
ans.append(node)
for next_node in graph[node]:
indegrees[next_node] -= 1
if indegrees[next_node] == 0:
queue.append(next_node)
if len(ans) != numCourses:
return []
else:
return ans
🧑🏻💻 0210) 위상 정렬 정석 문제. 주어진 b -> a 순서에 맞게, 그래프의 b 노드가 a 노드로 연결되고, indegree[a] += 1로 채워나가며 그래프와 indegree 1차원 list 완성. indegree = 0인 node부터 queue에 채워 나가고, queue를 while문으로 돌리며 popleft()할 때 ans list에 넣기. 그리고 뺀 node와 연결된 node들 indegree -= 1씩 진행해 간선의 수 1씩 빼기. 뺀 결과 0이 되는 node가 있다면 queue에 계속 넣기. 그 결과 ans에 들어간 node의 개수가 전체 그래프 node의 개수와 다르다면, cycle이 존재하는 것으로 [] 빈 리스트 출력. 그렇지 않다면 ans list 자체 출력
class Solution:
def minMeetingRooms(self, intervals: List[List[int]]) -> int:
intervals = sorted(intervals, key=lambda x: x[0])
heap = []
heappush(heap, intervals[0][1])
rooms = 1
for start, end in intervals[1:]:
if start >= heap[0]:
heappop(heap)
heappush(heap, end)
else:
rooms+=1
heappush(heap, end)
return rooms
🧑🏻💻 0253) 우선순위 큐 문제.
: 먼저 start time 기준으로 오름차순 정렬. 먼저 가장 start가 빠른 타임의 end time 넣은 뒤(타임 없는 경우는 존재 x), 이후 들어오는 타임의 start time과 현재 가장 빠른 end time과 비교.
* room A와 room B가 있다면, A의 end time과 B의 start time을 비교. B의 start time이 A의 end time보다 크거나 같다면, rooms + 1할 필요 없이 A를 heappop하고, B의 end time을 heappush. / 그 반대로 B의 start time이 A의 end time보다 작다면, rooms + 1하고 현재 B의 end time heappush
* 이 때, 앞선 여러 room 중 가장 end time이 빠른 경우를 뽑기 위해 우선순위 큐 사용해서 heap[0]과 B의 start time 비교.
* end time이 가장 빠른 room을 매번 뽑는 이유는 최대한 앞선 room을 제거하고 새로운 room으로 대체하기 위해 end가 가장 빠른 room을 찾는다
* 매 time 마다 데이터를 넣고 그 때마다 최댓값 또는 최솟값을 찾는 유형은 O(nlogn)인 우선순위 큐 자료구조를 필수로 활용해야 한다.
0692. Top K Frequent Words / 0271. Encode and Decode Strings


class Solution:
def topKFrequent(self, words: List[str], k: int) -> List[str]:
freq = Counter(words)
freq = sorted(freq, key = lambda x:(-freq[x],x))
return freq[:k]
🧑🏻💻 0692) value 내림차순, 그다음 key lexicographical order 순
class Codec:
def encode(self, strs: List[str]) -> str:
"""Encodes a list of strings to a single string.
"""
return 'π'.join(strs)
def decode(self, s: str) -> List[str]:
"""Decodes a single string to a list of strings.
"""
return s.split('π')
# Your Codec object will be instantiated and called as such:
# codec = Codec()
# codec.decode(codec.encode(strs))
🧑🏻💻 0271) encoding / decoding 진행할 때, non-ascii character 기준으로 각 문자열 사이에 해당 character 넣어서 encoding. decoding 진행 시 해당 character 기준 나눔.
1730. Shortest Path to Get Food

class Solution:
def getFood(self, grid: List[List[str]]) -> int:
row, col = len(grid), len(grid[0])
for i in range(row):
for j in range(col):
if grid[i][j] == '*':
my_loc = (i,j)
if grid[i][j] == '#':
food = (i,j)
dx,dy=[-1,1,0,0],[0,0,-1,1]
queue = deque([my_loc])
visited = [[False]*col for _ in range(row)]
grid[my_loc[0]][my_loc[1]] = 0
visited[my_loc[0]][my_loc[1]] = True
while queue:
x,y = queue.popleft()
for i in range(4):
nx,ny = x+dx[i],y+dy[i]
if 0<=nx<row and 0<=ny<col:
if not visited[nx][ny] and grid[nx][ny] == 'O':
visited[nx][ny] = True
grid[nx][ny] = grid[x][y] + 1
queue.append((nx,ny))
elif grid[nx][ny] == '#':
return grid[x][y] + 1
return -1
🧑🏻💻 1730) 전형적인 BFS 최단거리 유형. O이면서 non visited일 때 visited 처리하고 기존 graph의 값 + 1, 그리고 queue append / #이면 목적지 도달이므로, 기존 graph의 값 + 1한 결과를 출력.
'LeetCode Problems > Medium' 카테고리의 다른 글
| 🧑🏻💻 LeetCode Medium Collections 2 - 20 Problems (1) | 2024.10.31 |
|---|---|
| 🧑🏻💻 LeetCode Medium Collections 1 - 20 Problems (0) | 2024.09.09 |

댓글