02099 Election Results

# Import your libraries
import pandas as pd
# Start writing code
voting_results.head() #voter / candidate
#boolean indexing - filtering voters who didn't vote
voting_results = voting_results[~voting_results['candidate'].isna()] #boolean indexing(condiiton included)
#voting_results = voting_results.dropna()
#voter rate
voting_results['voter_rate'] = voting_results['voter'].apply(lambda x : 1 / (voting_results['voter'] == x).sum())
result = voting_results.groupby('candidate')['voter_rate'].sum()
#print(result)
result = result.reset_index() #index(new numbers), originial index -> new column
# print(result)
result[result['voter_rate'] == result['voter_rate'].max()] #row
result[result['voter_rate'] == result['voter_rate'].max()]['candidate'] #final ans
🥠
Q. 각 voter가 candidate에게 투표 진행. 이 때, 어떤 voter는 여러 명의 candidate에게 투표하였고, 두명에게 투표하면, 각 candidate은 1표가 아닌 0.5표를 나눠 가짐. 최고 득표 candidate 출력하기
★ 어떤 voter는 candidate 투표를 하지 않았음(null 처리 필요)
★ 두 명 이상에게 투표 시 각 candidate에게 그만큼 나눠가진 투표수 부여
* 첫번째 ★ 해결: boolean indexing으로 ~voting_results['candidate'].isna()인 조건을 indexing으로 넣어, null이 아닌 행만 filtering. 또는 dropna()로 한 방에도 가능
* 두번째 ★ 해결: 새로운 voter_rate 칼럼을 만들고, 각 행 별 apply() 함수 적용. 만들 함수는 lambda를 사용해 lambda x : 1 / (voting_results['voter'] == x).sum()) 내용 적용. voting_results['voter'] == x하면, 각 voter가 2개 이상일 경우, 그만큼 True가 생김. True는 1이고, False는 0이므로, sum()을 적용해, 각 row별 해당 voter가 몇 명인지 알 수 있음. 이 때, 동일 이름(ex Sally)이 3명 있다면, Sally의 득표 rate은 1이 아닌 1/3이 된다. 즉, 1 / (voting_results['voter'] == x).sum()) 적용함으로써 각 row의 voter rate 알 수 있다.
* groupby() 적용해 각 candidate별 voter_rate 합 구하기(groupby는 뒤에 aggregation 함수 필수 적용)
* reset_index() 적용해 candidate을 index가 아닌 새로운 column으로 변경
* boolean indexing으로 최댓값 voter_rate인 candidate 구하면 끝!
10060 Top Cool Votes

# Import your libraries
import pandas as pd
# Start writing code
yelp_reviews.head()
#boolean indexing
res = yelp_reviews[yelp_reviews['cool'] == yelp_reviews['cool'].max()]
#shown in dataframe along with selected columns
res[['business_name', 'review_text']]
🥠 Q. 가장 높은 cool votes 받은 행(more or equal than 1)의 busines_name과 review_text 두 행을 모은 dataframe 형태로 출력
* 두 개 이상의 selected rows를 dataframe 형태로 만들어서 출력하려면 res[['business_name', 'review_text']]와 같이 dataframe_name[[]]으로 [] 안에 []을 더 넣고, column names 나열.
10353 Workers With The Highest Salaries

# Import your libraries
import pandas as pd
# Start writing code
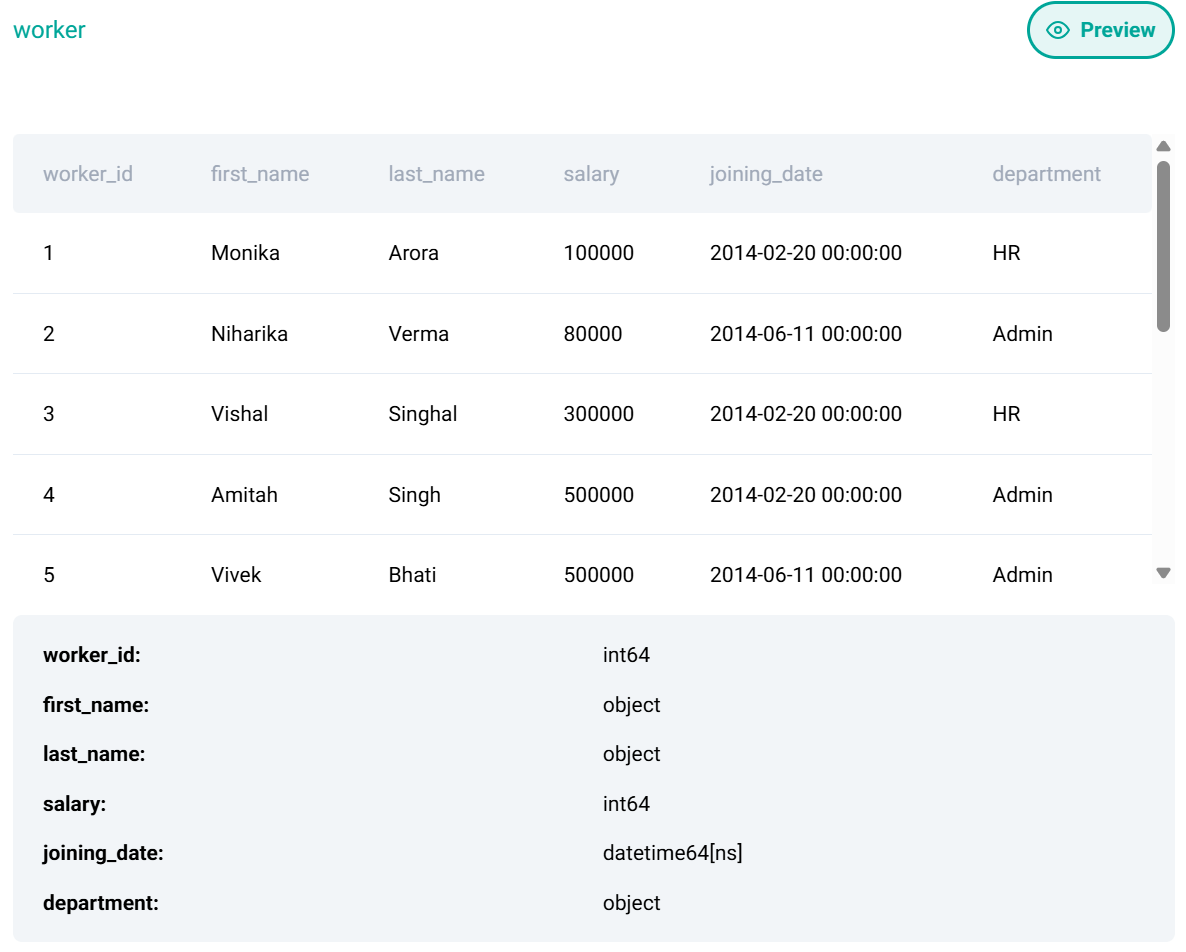
worker.head()
#inner-merge based on the same column 'id'
worker_merged = worker.merge(title, how = 'inner', left_on = 'worker_id' , right_on = 'worker_ref_id')
#inner-merge: show only intersected rows
#boolean indexing
worker_merged[worker_merged['salary'] == worker_merged['salary'].max()]['worker_title']
🥠 가장 높은 Salary를 받는 worker_title 구하기
* 문제는 간단하나, 테이블이 두 개이므로 merge 필수. worker.merge(title, how = 'inner', left_on = 'worker_id' , right_on = 'worker_ref_id') 코드를 사용해 worker_id와 worker_ref_id 공통 칼럼으로, 동일 id가 존재하는 행으로만 merge(inner-merge) 진행(left_on과 right_on으로 각 테이블의 key column 명 지정 가능)
* boolean indexing으로 salary 최댓값인 경우에만 worker_title 구하기
02102 Flags per Video


# Import your libraries
import pandas as pd
# Start writing code
user_flags.head()
user_flags = user_flags[user_flags['flag_id'].notnull()]
user_flags['name'] = user_flags['user_firstname'].astype(str) + ' ' + user_flags['user_lastname'].astype(str)
answer = user_flags.groupby(by='video_id')['name'].nunique().reset_index()
🥠 각 비디오 별로 중복 제외한 이름별 사용자 몇 명인지 정리해서 출력하는 문제
(1) 먼저 null 값 제거
(2) name 열 만들 때 firstname과 lastname 합쳐서 만들기. 이 때, astype(str) 함수 활용해서 각 열을 문자열로 바꿔서 합친 뒤 name 열 내용 생성
(3) 주어진 user_flags 데이터 프레임을 video_id로 groupby 진행하고 각 name별 nunique() 함수 사용해 실제 video 별 인원 수 정리해서 출력. 이 때, groupby 진행헀으므로 reset_index() 필수
02005 Share of Active Users


# Import your libraries
import pandas as pd
# Start writing code
fb_active_users.head()
df = fb_active_users[fb_active_users['status'] == 'open']
df_us = df[df['country'] == 'USA']
output = df_us.shape[0] * 100/ fb_active_users.shape[0]
🥠 조건에 맞는 행 필터링 진행 후, 전체 행 대비 조건에 맞는 행의 개수인 비율 출력
09610 Find Students At Median Writing


# Import your libraries
import pandas as pd
# Start writing code
sat_scores.head()
sat_scores[sat_scores['sat_writing'] == sat_scores['sat_writing'].median()]['student_id']
#sat_scores['sat_writing'].quantile(0.25)
🥠 sat_writing이 median 값에 해당하는 데이터의 student_id 출력하기
: median() 함수 바로 진행. 사분위 수 기준 P1, P3라면 quantile(0.25), quantile(0.75) 활용
09650 Top 10 Songs 2010


# Import your libraries
import pandas as pd
# Start writing code
billboard_top_100_year_end.head()
billboard_top_100_year_end = billboard_top_100_year_end[(billboard_top_100_year_end['year'] == 2010) & (billboard_top_100_year_end['year_rank'].between(1, 10))]
billboard_top_100_year_end.sort_values(by='year_rank', ascending=True)
billboard_top_100_year_end[['year_rank', 'group_name', 'song_name']].drop_duplicates()
🥠 2010년 빌보드 top 10의 목록 출력. 단, 랭크 기준 오름차순 출력하고, 동일 노래 중복 출력 금지
(1) between(1,10)을 활용해 rank의 1위부터 10위를 한번에 필터링 가능
(2) sort_values(by = 'year_rank', ascending = True)로 특정 열 기준 오름차순 정렬
(3) drop_duplicates() 함수 활용해 특정 데이터의 중복 열만 제거 가능
10182 Number of Streets Per Zip Code


# Import your libraries
import pandas as pd
# Start writing code
sf_restaurant_health_violations.head()
sf_restaurant_health_violations['street_str']=sf_restaurant_health_violations['business_address'].str.split()
sf_restaurant_health_violations['street_str']=sf_restaurant_health_violations['street_str'].apply(lambda x: x[1].lower() if x[0].isnumeric() else x[0].lower())
sf_restaurant_health_violations_grouped = sf_restaurant_health_violations.groupby('business_postal_code')['street_str'].nunique().reset_index()
sf_restaurant_health_violations_grouped.sort_values(by=['street_str','business_postal_code'],ascending=[False,True])
🥠 street_str에서 street 이름만 추출. 이름 추출하고, postal_code 별 street 개수 추출. 이후 두 열 기준에 따라 내림/오름차순 정렬
(1) .str.split()으로 먼저 문자열로 변환 뒤 split()으로 각 빈칸 별 split
(2) apply(lambda) 함수 적용해 if x[0].isnumeric()일 경우 x[1].lower() 아니면 x[0].lower()로 street name 선택
(3) groupby - nunique() - reset_index()
(4) sort_values()로 by 활용해 두 열 각각 내림/오름차순 정렬. 이 때 by와 ascending 각각[]로 넣음
10351 Activity Rank

# Import your libraries
import pandas as pd
# Start writing code
google_gmail_emails.head()
google_gmail_emails = google_gmail_emails.groupby('from_user').size().reset_index(name='total_emails').sort_values(by=['total_emails','from_user'],ascending=[False,True])
google_gmail_emails['Rank'] = range(1, len(google_gmail_emails) + 1)
#google_gmail_emails['rank'] = google_gmail_emails['total_emails'].rank(method='first', ascending=False)
google_gmail_emails
🥠 가장 많은 이메일 보낸 순으로 정렬(두가지 이상 기준)하고, rank 열 만들기
(1) groupby에서 size()로 각 group 내의 열 개수로 grouping 가능 - reset_index()안에 name 인자로 size()로 grouping된 새로운 각 그룹 내의 개수 열의 이름을 'total_emails'로 만들 수 있다.
(2) sort_values로 두 가지 이상의 열 기준 정렬
(3) 새로운 Rank 열 만들 때 range(1, len(df) +1) 또는 .rank(method = 'first', ascendig = False)로 만들 수 있다.
09915 Highest Cost Orders



# Import your libraries
import pandas as pd
# Start writing code
customers.head()
df = customers.merge(orders, how="inner", left_on="id", right_on="cust_id")
df = df[('2019-02-01' <= df['order_date']) & (df['order_date'] <= '2019-05-01')]
# df = df[df['order_date'].between('2019-02-01', '2019-05-01')]
df = df.groupby(['first_name','order_date'])['total_order_cost'].sum().reset_index(name='max_cost').sort_values('max_cost',ascending = False)
#df = df.groupby(['first_name','order_date'])['total_order_cost'].sum().to_frame('max_cost').reset_index().sort_values('max_cost',ascending = False)
res = df[df['max_cost'] == df['max_cost'].max()]
🥠 주어진 기한 별 데이터에서 각 customer 별 daily basis total_order_cost 최곳값을 찍은 customer 정보 출력
(1) 먼저 between() 또는 직접 부등식으로 datetime 정해진 기한별 데이터 filtering
(2) groupby 내에 두 가지 이상의 열을 기준으로 넣어 grouping 가능. reset_index()안에 name 인자를 넣어 total_order_cost 합계 이름 데이터 열을 새로운 열 이름으로 설정으로 가능. / 또는 reset_index()안에 name인자를 안넣고, 어차피 groupby()의 결과는 Series이므로 to_frame()을 적용해 to_frame()안에 새롭게 만들 열의 이름을 넣으면 됨. to_frame()은 Series를 Dataframe으로 바꾸는 함수.
(3) boolean indexing으로 최댓값 filtering
02064 Difference Between Times


# Import your libraries
import pandas as pd
# Start writing code
marathon_male.head()
male=(abs(marathon_male['gun_time']-marathon_male['net_time'])).mean()
female=(abs(marathon_female['gun_time']-marathon_female['net_time'])).mean()
abs(female-male)
🥠두 column 사이의 차이(절댓값)의 평균을 위 코드 두 줄과 같이 한 방에 구할 수 있다.
(★) 02014 Hour With The Highest Order Volume


# Import your libraries
import pandas as pd
# Start writing code
postmates_orders.head()
postmates_orders["hour"] = postmates_orders[ "order_timestamp_utc" ].dt.hour
#.apply(lambda x: x.hour)
postmates_orders["date"] = postmates_orders["order_timestamp_utc"].dt.date
result = postmates_orders.groupby([postmates_orders['date'], postmates_orders['hour']])['id'].count().reset_index(name='n_orders')
result = result.groupby('hour')['n_orders'].mean().reset_index() #name x -> n_orders
result[result['n_orders'] == result['n_orders'].max()]
🥠 어떤 날의 어떤 시간이 가장 많은 order_volumn 평균값을 가지는 지 알아보는 문제
* (1) hour와 date 칼럼을 만들고(dt.hour와 dt.date 사용), date와 hour 순서대로 groupby 진행해 각 날짜의 각 시간별 주문 개수 구하기
(reset_index 인자로 ()안에 새롭게 만들어지는 칼럼 이름 넣기)
* (2) 다시 hour로 grouping을 진행해 hour별 주문개수 평균을 구하기
* (3) 최댓값 filtering
Q. groupby를 두 번 진행하지 않고, 먼저 각 시간별로 grouping할 수는 없을까?
A. 3/11일 17시 order가 3개, 3/12일 17시 order가 1개라면, 애초에 hour로만 grouping하면, count는 4가 된다. 하지만, day별 hour별 average의 최댓값이기에, 우린 먼저 day별 hour별 grouping 진행 필수. 그러면 3/11일 17시는 3, 3/12일 17시는 1이 되고, hour로 grouping하면 평균값인 2가 나온다. 따라서, 중복 데이터로 인해 groupby를 두 번 진행해야 한다는 점에 매우 주의
02042 Employees' Years In Service


# Import your libraries
import pandas as pd
# Start writing code
uber_employees.head()
uber_employees['still_employed'] = uber_employees['termination_date'].apply(lambda x: 'yes' if pd.isna(x) else "no")
uber_employees['termination_date'] = uber_employees['termination_date'].fillna(pd.to_datetime('2021-05-01'))
uber_employees['years_worked'] = ((uber_employees['termination_date'] - uber_employees['hire_date']).dt.days)/365
result = uber_employees[uber_employees['years_worked'] > 2][['first_name', 'last_name', 'years_worked', 'still_employed']]
🥠 근무기간 2년 넘은 경우의 사원들이 현재도 employed되었는 지 알아보는 문제
(1) 먼저 lambda를 활용해 isna(x)로 yes나 no 데이터 넣는 apply() 함수 적용
(2) fillna()로 null인 경우 2021-05-01을 넣는데 pd.to_datetime() 활용. 그리고 years_worked 구하고 (dt.days/365) >2에 맞는 데이터만 관련 내용 출력
02153 Average On-Time Order Value


# Import your libraries
import pandas as pd
# Start writing code
delivery_details.head()
delivery_details['duration_time_minute'] = (delivery_details['delivered_to_consumer_datetime'] - delivery_details['customer_placed_order_datetime']).dt.total_seconds()/60
delivery_details_under_45 = delivery_details[delivery_details['duration_time_minute'] <= 45]
delivery_filtered = delivery_details[delivery_details['driver_id'].isin(delivery_details_under_45['driver_id'].drop_duplicates())]
delivery_filtered.groupby('driver_id')['order_total'].mean().reset_index(name='avg_order_value')
🥠 정의한 duration time이 45분 이하인 order가 적어도 한 개 있는 driver의 average order value 구하기.
★ 주의점) duration time이 45분 이하인 order만 모아서 average order value를 구하는 게 아니라, duration time이 45분 초과인 order가 있는 driver라도, driver의 order 중 duration time이 45분 이하인 order가 존재한다면, 해당 driver의 45분 초과인 order까지 모두 포함해서 average order value 구하기.
(1) duration time column 만들기(datetime - datetime 하면 timedelta data type이 나오고, total_seconds()/60을 활용해 duration minute 계산 가능
(2) 별도의 under_45 dataframe만들어서 새롭게 만든 column이 45분 이하일 때의 정보만 모은 곳에서의 driver_id 구하기.
(3) 구한 driver_id의 drop_duplicates() 함수 써서 중복 없는 driver id에 기존 driver_id가 포함되는 지 안 되는 지 isin()으로 판단
(4) driver_id가 포함되는 경우만 delivery_filtered로 최종 dataframe으로 판단.
(5) 마지막으로 groupby 진행해서 mean()함수로 avg_order_value 구하기.
★ 시간 관련 data type) datetime과 timedelta 2개 정확히 구분하기
02113 Extremely Late Delivery

# Import your libraries
import pandas as pd
from datetime import timedelta
# Start writing code
delivery_orders.head()
delivery_orders = delivery_orders[delivery_orders['actual_delivery_time'].notnull()]
delivery_orders['is_extreme'] = (delivery_orders['actual_delivery_time'] > (delivery_orders['predicted_delivery_time'] + timedelta(minutes=20))).astype(int)
#delivery_orders['month'] = (delivery_orders['order_placed_time'].dt.month)
delivery_orders['month'] = delivery_orders['order_placed_time'].dt.to_period('M')
res = delivery_orders.groupby('month')['is_extreme'].agg(lambda x: x.mean()*100).reset_index(name='perc_extremely_delayed')
res
🥠 년-월별 extremely late orders의 비율을 %로 나타내기
(1) 먼저, extreme 여부 column 생성) datetime + timedelta(duration time)가 가능하며, timedelta(minutes=20)를 쓰기 위해서는 직접 from datetime import timedelta 사용
(2) 이 때, 년-월 객체로 나누기 위해 dt.to_period('M') 사용. to_period()는 기간단위의 객체로 변환
★ dt.month는 year 포함하지 않은 말 그대로 month 자체이므로 year포함해서 출력 x
(3) 기간단위인 '월' 단위의 객체로 바꾼 ['month']를 groupby로 진행하고 is_extreme을 가지고 agg() 함수 진행해 x.mean()*100으로 실제 평균값을 구할 수 있다. (agg말고 apply도 적용 가능)
09601 Find the Best Day for Trading AAPL Stock


# Import your libraries
import pandas as pd
# Start writing code
aapl_historical_stock_price.head()
aapl_historical_stock_price['day_of_month'] = aapl_historical_stock_price['date'].dt.day
res1 = aapl_historical_stock_price.groupby('day_of_month')['open'].mean().reset_index()
res2 = aapl_historical_stock_price.groupby('day_of_month')['close'].mean().reset_index()
res = res1.merge(res2, how='inner', left_on = 'day_of_month', right_on = 'day_of_month')
res['diff'] = res['close']-res['open']
res[res['diff'] == res['diff'].max()][['day_of_month', 'open', 'close']]
🥠 각 월 별 일중, open과 close의 차이가 가장 큰 일자 출력하기
* 여기서 주의점은, '일'은 월 내의 모든 '일'을 뜻한다. 따라서, 3월 1일이나 4월 1일이나 같은 1일로 간주. 따라서 .dt.day 사용 가능
09762 Find the Day of the Week that most People check-in


# Import your libraries
import pandas as pd
# Start writing code
airbnb_contacts.head()
airbnb_contacts['dayofweek'] = airbnb_contacts['ds_checkin'].dt.dayofweek
res = airbnb_contacts.groupby('dayofweek').size().reset_index(name='size')
res[res['size'] == res['size'].max()]
🥠 day-of-week별 가장 많은 방문 횟수 구하기
(1) day-of-week은 dt.dayofweek 활용
(2) groupby().size()로 각 그룹별 개수 size 구하기
02154 Top 2 Sales Time Combinations

def categorize_time(hour):
if hour < 12:
return 'Morning'
elif 12 <= hour <= 15:
return 'Early Afternoon'
else:
return 'Late Afternoon'
# Import your libraries
import pandas as pd
# Start writing code
sales_log.head()
sales_log['day_of_week'] = sales_log['timestamp'].dt.day_name()
sales_log['time_of_day'] = sales_log['timestamp'].dt.hour.apply(categorize_time)
res = sales_log.groupby(['day_of_week','time_of_day']).size().reset_index(name='total_orders')
top_orders = res['total_orders'].nlargest(2)
res[res['total_orders'].isin(top_orders)].sort_values(by='total_orders', ascending = False)
🥠day_of_week 중 time_of_day 중 order의 건수 top 2(건수 중복이면 모두 포함) 정보 출력
(1) 먼저 day_of_week를 datetime column에서 뽑을 건데, 0~6 숫자가 아닌 Saturday, Friday와 같이 요일 이름으로 뽑을려면 dt.day_name() 활용
(2) time_of_day는 apply() 함수를 따로 적용하여, 별도의 함수 categorize_time에서 여러 분기문으로 처리
(3) groupby 두 칼럼 grouping 진행 / 각 group별 size 개수이므로 size() 적용
(4) 일단 중복 데이터 포함 top 순위 데이터 고르려면 nlargest(x)로 내용을 뽑고, isin() 활용해 해당 모든 내용 가져오기
* 위 문제 핵심 코드 키워드 정리
(1) boolean indexing을 활용한 ~isna()로 null data 포함 행 deletion
(2) apply() 활용해 lambda x : 1 / (voting_results['voter'] == x).sum()) 함수로 각 data의 share 구하기
(3) groupby + aggregation
(4) reset_index(): index 0~ 지정 + index된 부분은 새로운 column으로 지정
(5) dataframe화 하기 위해 [[]]
(6) merge - inner merge / left_on / right_on
(7) 두 문자열 열 합칠 때 각 열 astype(str) 활용해서 각각 붙여 새로운 열 생성
(8) nunique()은 각 열의 데이터 중복 제거 고유값 개수
(9) df.shape활용해 전체 행의 개수 및 열의 개수 알 수 있음
(10) median(), quantile(0.2.5), quantile(0.75)
(11) between() 적용해 특정 열의 범위에 맞는 데이터만 필터링 / sort_values(by = '열 이름')으로 특정 열 기준 오름/내림차순 / drop_duplicates() 활용해 특정 열의 모음만 중복된 데이터 제거 가능
(12) .str.split()으로 열의 각 내용을 문자열로 변환하고 빈칸 별 split() / apply(lambda x)로 if문에 따라 내용 추출 / sort_values()로 두 개 이상의 열 정렬 가능(by와 ascending 값을 정렬 우선순위에 따라 []안에 넣으면 된다.
(13) groupby()내의 그룹화된 열의 개수로 grouping하고 싶다면 groupby('열 이름').size()로 가능, 이 때 개수라는 새로운 열이 만들어지므로 reset_index()안에 name 인자로 새로운 열 이름 지정 가능(또는 groupby 결과 Series를 to_frame()으로 데이터프레임으로 바꾸면서 to_frame()안에 이름 설정도 가능)
(14) 어떤 데이터의 순위 열 만들 때, .rank(method = 'first', ascendig = False)로 지정 가능. method = 'first'는 동일 순위 시, 위 열 먼저 앞의 등수 부여
(15) datetime filtering 부등식 또는 between() 활용
(16) groupby시 두 가지 이상의 열을 넣어 기준으로 grouping 가능.
(17) 두 칼럼 사이의 절댓값의 평균값 자체를 한 방에 구할 수 있음.
(18) 02014 문제를 보며 groupby 두번의 필요성 기억 / .dt.hour & .dt.date 활용
'Data Science Fundamentals > Pandas&Numpy and Questions' 카테고리의 다른 글
| 🥰 StrataScratch PythonPandas Easy I - 2 Solved (0) | 2025.03.16 |
|---|---|
| map & applymap & apply(for dataframe & Series) (1) | 2024.06.02 |
| dataframe 꾸미기 (1) | 2023.01.22 |
| Numpy fundamentals 2/2 (0) | 2023.01.16 |
| pandas Tricks (Kevin by DataSchool) 완료! COMPILATION (0) | 2022.04.18 |

댓글