🕵🏻 우리가 주어진 data는 대게 정돈된 structured data가 아닐 확률이 높다. 특히 web에 흩뿌려진 data를 가져오는 경우가 종종 있는데, 이 때 web scraping이라는 기법을 사용함! (개인적으로 너무 재밌는 web scraping 🏄🏻♀️)
Q. Web Scraping vs. Web Crawling?
≫ web scraping은 우리가 찾을 'data'에 초점을 둔 것 / web crawling은 우리가 찾을 장소인 'url'에 초점을 둔 것. 대게 crawling과 scraping 과정을 병행한다. (web scraping is about extracting the data from one or more websites. While crawling is about finding or discovering URLs or links on the web.)
≫ crawling으로 url을 찾고, scraping으로 찾은 url 화면 내의 data를 뽑아냄! (you need to combine crawling and scraping. So you first crawl - or discover - the URLs, download the HTML files, and then scrape the data from those files. This means you extract data and do something with it, like storing it in a database or further processing it.)
≫ crawling 예시
1> search engines crawl the web so they can index pages and display them in the search results
→ search engine을 통해 찾고자 하는 page 위치를 알아냄
2> when you have one website that you want to extract data from - in this case you know the domain - but you don't have the page URLs of that specific website. So you don't know what pages to scrape. So first you create a crawler that will output all the page URLs that you care about - it can be pages in a specific category on the site or in specific parts of the website. Or maybe the URL needs to contain some kind of word for example and you collect all those URLs - and then you create a scraper that extracts predefined data fields from those pages
→ 도메인은 알지만 어떤 page를 가져올 지 아직 정하지 않았을 때 crawler를 통해 모든 page 각각에 해당하는 url을 출력한다.
!-- 그러면 data를 가져올 공간인 web에 대해서 r아보za --!
1. 웹사이트 구조
🕵🏻 웹 사이트의 뼈대를 완성하는 언어는 HTML이다. 흔히 들어본 CSS나 JS는 꾸며주는 용도로, 부가적인 기능에 쓰임.
(CSS는 꾸미고, JS는 실행시키고!)(티스토리 스킨편집도 모두 HTML 언어를 수정하는 것!)
→ 일단 HTML은 Hyper Text Markup Language의 줄임말로, 웹 브라우저에 보여지는 문서를 위한 표준 마크업 언어이다.
(여기서 markup language란 프리스타일로 단순히 글을 작성한 언어가 아니라, tag를 달아 작성한 구조적인 언어를 뜻함)
(↓↓↓ HTML5, CSS3 관련 개념 하단 참고 ↓↓↓)
Crawling에 필요한 HTML5 & CSS3 (간단 정리)
1. HTML5 [1] 개요 및 개념 * 표준 web이라고 부르는 HTML5는 주로 내용을 표현하는 것에 중점을 둠 * HTML 요소를 통해 웹 페이지 구조와 의미를 정의한다 * 시작 태그와 끝 태그를 정의하고, 그 사이
sh-avid-learner.tistory.com
→ mozilla 공식 docu에 의하면 web site는 아래와 같은 공통적인 요소를 공유함!
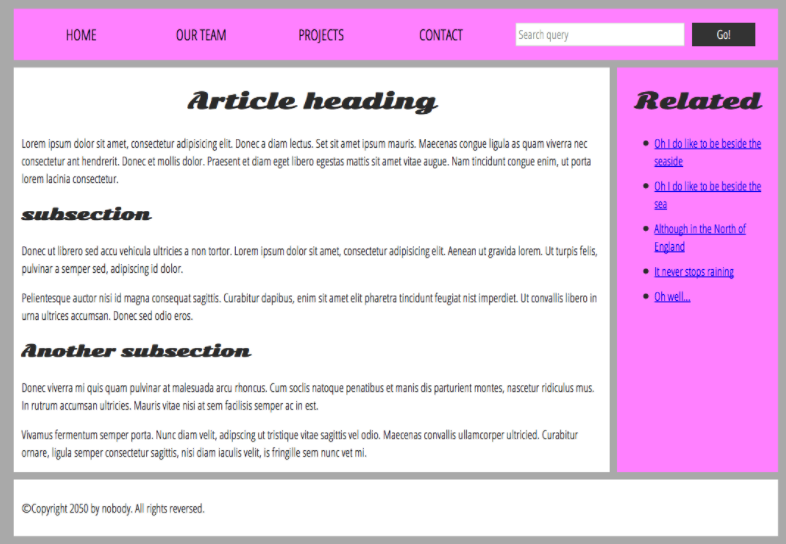
① header: Usually a big strip across the top with a big heading, logo, and perhaps a tagline. This usually stays the same from one webpage to another. (웹사이트에 큰 제목이 주로 들어가는 대표적인 box - header)
② navigation bar: Links to the site's main sections; usually represented by menu buttons, links, or tabs. Like the header, this content usually remains consistent from one webpage to another — having inconsistent navigation on your website will just lead to confused, frustrated users. Many web designers consider the navigation bar to be part of the header rather than an individual component, but that's not a requirement; in fact, some also argue that having the two separate is better for accessibility, as screen readers can read the two features better if they are separate. (사이트의 메인섹션 - 다른 부분으로 연결해주는 일종의 여러 연결고리 box)
③ main content: A big area in the center that contains most of the unique content of a given webpage, for example, the video you want to watch, or the main story you're reading, or the map you want to view, or the news headlines, etc. This is the one part of the website that definitely will vary from page to page! (떠있는 해당 화면의 주요 웹페이지 내용)
④ sidebar: Some peripheral info, links, quotes, ads, etc. Usually, this is contextual to what is contained in the main content (for example on a news article page, the sidebar might contain the author's bio, or links to related articles) but there are also cases where you'll find some recurring elements like a secondary navigation system. (주로 main content와 연관되어 있는 서브 내용이 나와 있는 창)
⑤ footer: A strip across the bottom of the page that generally contains fine print, copyright notices, or contact info. It's a place to put common information (like the header) but usually, that information is not critical or secondary to the website itself. The footer is also sometimes used for SEO purposes, by providing links for quick access to popular content. (주로 덜 중요한 내용이나 참고할 부분들, page 권한, 저작권, 연락처와 같은 내용들이 하단에 표시됨)
- 하단 그림 web site 예시 -
(해당 예시에는 header에 navigation bar가 들어가 있다.
중간에 main content, 우측에 sidebar, 그리고 하단에 footer 존재)
2. DOM(Document Object Model)
👩🔬 '문서 객체 모델'이라고도 불리는 이 DOM은 HTML, XML 등 문서의 프로그래밍 인터페이스이다. DOM을 통해 프로그래밍 언어를 통해서 문서에 접근할 수 있게 해준다. 즉 DOM은 문서와 '내가 직접 자유자재로 짤 수 있는 프로그래밍 언어' 사이의 다리 역할!
→ HTML, XML 문서를 위한 일종의 API 종류 중 하나
→ 트리구조와 같이 논리적인 구조를 갖고 있음
→ 주어진 문서를 DOM parser를 이용해 parsing하면, 해당 문서의 모든 element를 포함한 tree 형태의 구조를 가져올 수 있음
👩🔬 DOM의 장점?
→ Used for manipulating document structures. (문서를 손쉽게 '프로그래밍 언어 만으로' 조작 가능!)
→ Data persists in memory. (data가 메모리에 계속 남음!)
→ You can go forwards and backward in the tree (random access) (순서 필요없이 tree 계층 구조의 모든 element에 자유롭게 접근 가능)
→ You can make changes directly to the tree in memory. (메모리에 남은 tree 구조 내용을 바로 변경할 수 있음!)
👩🔬 DOM 여러 method (대표적인 것만 - 제일 많이 쓰이는!)
| DOM method 종류 | method 기능 |
| getElementsbyTagName | tag 이름을 가진 문서 element들 return |
| getElementById | 해당 id와 일치하는 tag element return |
| getElementsByClassName | 해당 class에 속하는 모든 tag들 elements return |
| querySelector | 해당 selector와 일치하는 element return |
| querySelectorAll | 해당 selector와 일치하는 모든 elements return |
👩🔬 실제 web page crawling + scraping할 때 거대한 data를 일일이 text 취급을 해서 가져오기엔 너무 비효율적이다. 따라서 우리는 DOM method를 통해 원하는 DOM tree로 표현된 내용 중 일부 element만 가져오는 활동을 해야할 것임!
👩🔬 실습> chrome browser에 원하는 page를 띄우고 우클릭 → 검사 버튼 → Console 창 → DOM method code를 통해 원하는 element 불러오기 가능!
- 아래와 같이 DOM은 tree 형태로 여러 element들이 나열되어 구성! -

* 출처1) <참고한 강좌> https://www.youtube.com/watch?v=i0FN-OwJ7QI&t=130s
* 출처2) <html> https://en.wikipedia.org/wiki/HTML
* 출처3) mozilla 공식 docu https://developer.mozilla.org/en-US/docs/Learn/HTML/Introduction_to_HTML/Document_and_website_structure
* 출처4) web scraping & web crawling https://www.zyte.com/learn/difference-between-web-scraping-and-web-crawling/
* 출처5) DOM https://www.w3.org/TR/REC-DOM-Level-1/introduction.html
'Python Language > Web Crawling+Scraping' 카테고리의 다른 글
| (예제) - 한국 도쿄올림픽 medal count 가져오기 - (0) | 2022.03.22 |
|---|---|
| HTML 문서를 BeautifulSoup으로 검색하기 (+re module) (0) | 2022.03.21 |
| Crawling/Scraping에 필요한 HTML5 & CSS3 (간단 정리) (0) | 2022.03.21 |

댓글