Q. 데이터를 재구조화하는 방법?
A. stack() & unstack() 사용! 🙂
¶ stack() docu
https://pandas.pydata.org/docs/reference/api/pandas.DataFrame.stack.html
DataFrame.stack(level=- 1, dropna=True)
'Stack the prescribed level(s) from columns to index. Return a reshaped DataFrame or Series having a multi-level index with one or more new inner-most levels compared to the current DataFrame. The new inner-most levels are created by pivoting the columns of the current dataframe:
→ if the columns have a single level, the output is a Series;
→ if the columns have multiple levels, the new index level(s) is (are) taken from the prescribed level(s) and the output is a DataFrame.
≫ 즉 데이터프레임이나 시리즈 형태의 data에서 모든 column을 index로 보내 multi-index 형태로 보내는 함수를 말함!
≫ ex) single-level columns
exercise = sns.load_dataset('exercise')
exercise.drop(columns='Unnamed: 0', inplace=True)
exercise.index.nlevels #1
exercise.stack()
exercise.stack().index.nlevels #2
- multi-level index를 가지는 한 개의 series로 변환하였다 -
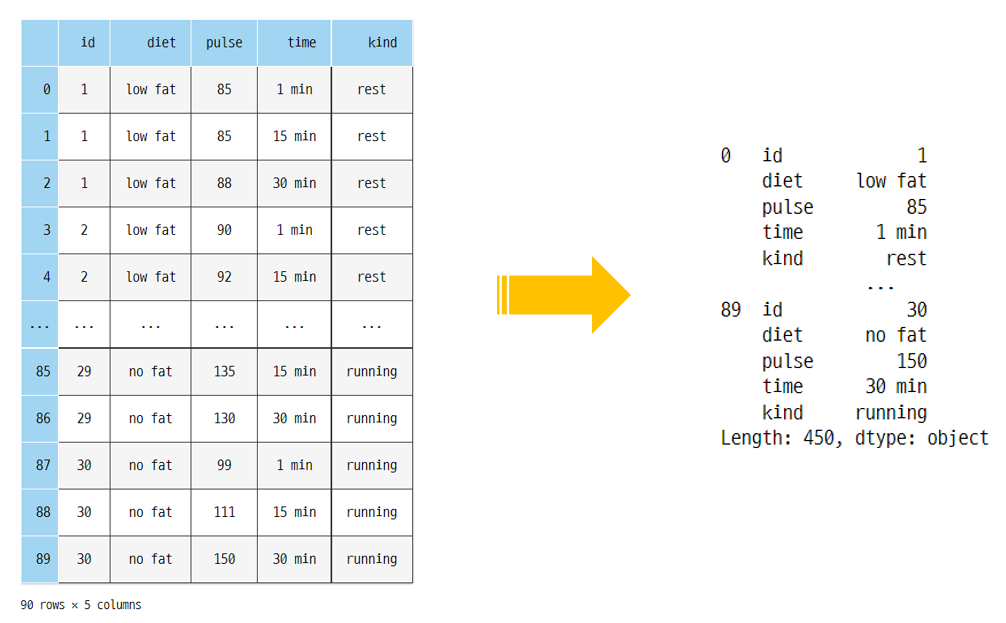
→ 즉! stack() 이전에는 dataframe의 index는 level이 1이었지만 stack() 결과 column들이 한 개의 index로 추가되면서 multi-level index로 바뀌고 index level은 2로 바뀜!
→ index는 기존 0~89 그대로이지만 각 index마다 column 행들이 들어가면서 2-level index로 변했음을 확인할 수 있다
→ 그 결과 각 index별 모든 column 별 결과가 각 row로 출력되면서 index행(90개) * column행(5개) = 450개의 행으로 나옴 확인 가능
≫ ex) multi-level columns
multicol1 = pd.MultiIndex.from_tuples([('weight', 'kg'),
('personality', 'type')])
df_multi_level_cols1 = pd.DataFrame([[1, 'ENFJ'], [2, 'INFP']],
index=['cat', 'dog'],
columns=multicol1)
df_multi_level_cols1.stack()
- multi-level의 column은 stack() 결과 dataframe 형태로 반환 -

→ column 자체에 level이 있을 경우 index로 들어갈 때 column level 간의 모든 조합에 대한 결과를 출력해줌! (그래서 NaN이 생김!)
∧ 여기서 stack 개념과 melt 개념에 대해 헷갈릴 수 있다! ∧
→ stack을 통해 column이 여러 index로 녹아 들어가서 multi-level index로 만들고 단일 level column들이면 series로 반환해준다
→ 하지만 melt를 통해서는 column이 일종의 variable로 index가 아닌 형태로 변환되며 일종의 tidy data - dataframe으로 반환해줌!
(↓↓↓↓↓ melt - tidy data 자세한 개념은 아래 포스팅 참조 ↓↓↓↓↓)
Tidy Data
* 실제 사용되는 데이터는 하나의 완벽한 dataset이 아닌 여러 개로 쪼개진 경우가 많다! → 따라서 분석하기 용이하게 하나의 dataset으로 만들기 위한 과정이 필요 1. Tidy Data란? "각 변수가 열이
sh-avid-learner.tistory.com
- stack과 melt의 차이점! 그림으로 한 눈에 이해하자 -

¶ unstack() docu
https://pandas.pydata.org/docs/reference/api/pandas.DataFrame.unstack.html
DataFrame.unstack(level=- 1, fill_value=None)
'Pivot a level of the (necessarily hierarchical) index labels. Returns a DataFrame having a new level of column labels whose inner-most level consists of the pivoted index labels. If the index is not a MultiIndex, the output will be a Series (the analogue of stack when the columns are not a MultiIndex).'
"stack()과 반대개념!"
'multi-level index를 풀어낸다!'
≫ ex) unstack 결과
index = pd.MultiIndex.from_tuples([('one', 'a'), ('one', 'b'),
('two', 'a'), ('two', 'b')])
s = pd.Series(np.arange(1.0, 5.0), index=index)
s
s.unstack(level=0)
s.unstack(level=1)
- 위는 level 1 기준 unstack, 아래는 level 0 기준 unstack -

→ multi-level index 기준 왼쪽부터 level 0부터 시작한다
(level에 index 이름을 넣어도 가능!)
😽 stack() & unstack() 끝!
* 썸네일 출처) https://www.data.ai/kr/apps/google-play/app/com.mondayoff.stack/

댓글