1) Getting Started with SQL
Q1) What is SQL? (Structured English Query Language)
= a language used for relational databases to query or get data out of a database
- 더 자세한 설명은 하단 포스팅 참조 -
why SQL? & Relational Databases
🧡 Structured Query Language 🧡 🦄 1970년대에 등장했으면 다소 '올드하다'는 이미지를 가져다 줄 수 있겠지만, 전 세계 기업들 - 페이스북, 인스타, 에어비앤비, 우버 등등 -이 보유한 대용량의 data는
sh-avid-learner.tistory.com
Q2) What is a Database? = a repository of data
- a program that stores data
-
≫ a relational database
-
SELECT column1, column2, ...
FROM table_name
WHERE condition
;

SELECT Title, Director, Writer FROM FilmLocations;
SELECT Title, ReleaseYear, Locations FROM FilmLocations WHERE ReleaseYear >= 2001;
SELECT Locations, FunFacts FROM FilmLocations;
SELECT Title, ReleaseYear, Locations FROM FilmLocations WHERE ReleaseYear <= 2000;
SELECT Title, ProductionCompany, Locations, ReleaseYear FROM FilmLocations WHERE Writer<>"James Cameron";
Q) Retrieve the number of rows from the "FilmLocations" table
SELECT COUNT(*) FROM FilmLocations;
Q) Retrieve the number of locations of the films which are written by James Cameron
SELECT COUNT(Locations) FROM FilmLocations WHERE Writer = "James Cameron";
Q) Retrieve the number of films shot at Russian Hill
SELECT Count(Title) FROM FilmLocations WHERE Locations = "Russian Hill";
Q) Retrieve the name of all films without any repeated titles
SELECT DISTINCT Title FROM FilmLocations;
Q) Retrieve the number of release years of the films distinctly, produced by Warner Bros. Pictures
SELECT COUNT(DISTINCT ReleaseYear) FROM FilmLocations WHERE ProductionCompany = "Warner Bros. Pictures";
≫ DISTINCT applies to the column 'ReleaseYear' and 'the number of' means COUNT
Q) Retrieve the name of all unique films released in the 21st century and onwards, along with their release years
SELECT DISTINCT Title, ReleaseYear FROM FilmLocations WHERE ReleaseYear >= 2001;
≫ DISTINCT only applies to Title, not to ReleaseYear
≫ 21st centry does NOT include a year of 2000
≫ 'along with their release years' = means SELECT ReleaseYear
Q) Retrieve the names of all the directors and their distinct films shot at City Hall
SELECT DISTINCT Title, Director FROM FilmLocations WHERE Locations = "City Hall";
Q) Retrieve the first 25 rows from the "FilmLocations" table
SELECT * FROM FilmLocations LIMIT 25;
Q) Retrieve the first 15 rows from the "FilmLocations" table starting from row 11
SELECT * FROM FilmLocations LIMIT 15 OFFSET 10;
≫ OFFSET 10 = retrieve from the 11th row. (doesn't include the 10th row)
Q) Retrieve the next 3 film names distinctly after first 5 films released in 2015
SELECT DISTINCT Title FROM FilmLocations WHERE ReleaseYear = 2015 LIMIT 3 OFFSET 5;
≫ it said 'after' = so OFFSET 5 means it retrieves from the 6th row
* INSERT, UPDATE, DELETE *
INSERT INTO table_name (column1, column2, ...)
VALUES (value1, value2, ...)
;
UPDATE table_name
SET column1 = value1, column2 = value2, ...
WHERE condition
;
DELETE FROM table_name
WHERE condition
;
Q) SELECT * FROM Instructor;

Q) Insert a new instructor record with id 4 for Sandip Saha who lives in Edmonton, CA into the "Instructor" table
INSERT INTO Instructor(ins_id, lastname, firstname, city, country)
VALUES(4, 'Saha', 'Sandip', 'Edmonton', 'CA');
Q) Insert two new instructor records into the "Instructor" table.
First record with id 5 for John Doe who lives in Sydney, AU. Second record with id 6 for Jane Doe who lives in Dhaka, BD
INSERT INTO Instructor(ins_id, lastname, firstname, city, country)
VALUES(5, 'Doe', 'John', 'Sydney', 'AU'), (6, 'Doe', 'Jane', 'Dhaka', 'BD');
Q) Update the city for Sandip to Toronto
UPDATE Instructor
SET city = 'Toronto'
WHERE firstname = "Sandip";
Q) Update the city and country for Doe with id 5 to Dubai and AE respectively
UPDATE Instructor
SET city = 'Dubai', country = 'AE'
WHERE ins_id = 5;
Q) Remove the instructor record of Doe whose id is 6
DELETE FROM Instructor
WHERE ins_id = 6;
2) Introduction to Relational Databases and Tables
* Relational Model *
= most used data model
- TABLES → logical data, physical data, physical storage data independence
* ER data model(entity relationship data model) = an alternative to a relationship data model
- ER diagram - represents entities(tables) & their relationships -

- proposes thinking of a database as a collection of entities
-
-
* Primary key)
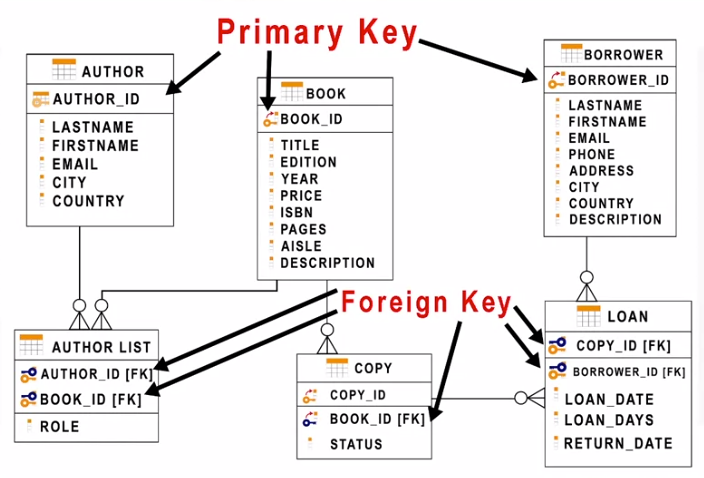
* Types of SQL Statements (DDL vs. DML)
≫ DDL(Data Definition Language) Statements: define, change, or drop data
ex) CREATE, ALTER, TRUNCATE, DROP
- CREATE: creating tables and defining its columns
- ALTER:
- TRUNCATE: deleting data in a table but not the table itself
- DROP: deleting tables
≫ DML(Data Manipulation Language) Staements: to read, modify data in tables
ex) CRUD operations) INSER, SELECT, UPDATE, DELETE
- INSERT: inserting a row or several rows of data into a table
- SELECT: reads or selects row or rows from a table
- UPDATE: edits row or rows in a table
- DELETE: removes a row or rows of data from a table
* CREATE Table Statement *
CREATE TABLE table_name
(
column_name_1 datatype optional_parameters.
column_name_2 datatype,
...
column_name_n datatype
)
e.g 1)
CREATE TABLE provinces(
id char(2) PRIMARY KEY NOT NULL,
name varchar(24)
)
- char(2): fixed length of 2 / varchar(24): character string of a variable length, can be up to 24 characters long
e.g 2)
CREATE TABLE author (
author_id CHAR(2) PRIMARY KEY NOT NULL,
lastname VARCHAR(15) NOT NULL,
firstname VARCHAR(15) NOT NULL,
email VARCHAR(40),
city VARCHAR(15),
country CHAR(2)
)
- NOT NUll) ensures that this field has no null value
* ALTER Table Statement *
- we do not use parantheses
- we use ALTER statement to add or remove columns
- modify the data type of columns, add or remove keys, add or remove constraints
ALTER TABLE table_name
ADD COLUMN column_name data_type column_constraint;
ALTER TABLE table_name
DROP COLUMN column_name;
ALTER TABLE table_name
ALTER COLUMN column_name SET DATA TYPE data_type;
ALTER TABLE table_name
RENAME COLUMN current_column_name TO new_column_name;
≫ datatype e.g = BIGINT) hold a number up to 19 digits long
* DROP Table Statement *
- the data will be deleted alongside with the table
- It is quite common to issue a DROP before doing a CREATE in test and development scenarios
DROP TABLE <table name>;
* Truncate Statement *
- to delete data in a table rather than a table itself (delete all rows in a table)
TRUNCATE TABLE <table name>
IMMEDIATE;
- IMMEDIATE) specifies to process the statement immediately and that it cannot be undone
3) Intermediate SQL
* Using String Patterns and Ranges *
# Retrieving Rows - using a String Pattern
- WHERE requires predicate (predicate = an expression that evaluates to True, False, or Unknown)
- LIKE predicate (WHERE <columname> LIKE <string pattern>)
ex1) WHERE firstname like 'R%'
ex2) WHERE pages >=290 AND pages <=300 (WHERE pages between 290 and 300)
ex3) WHERE country IN ('AU', 'BR') (the IN operator allows us to specify a set of values in a WHERE clause)
* Sorting Result Sets *
# Using the ORDER BY clause
SELECT title from book ORDER BY title
- by default the result set is sorted in ascending order
SELECT title FROM book ORDER BY title DESC
SELECT title, pages from book ORDER BY 2
≫ 2 specifies 'pages' column in Book table
* Grouping Result Sets *
# Eliminating Duplicates - DISTINCT clause
SELECT DISTINCT(country) FROM Author
SELECT country, COUNT(country) as Count from Author GROUP BY country
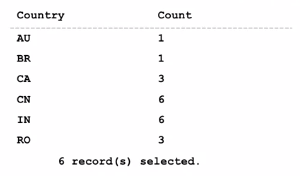
# Restricting the Result set - HAVING clause
(having clause only works with group by clause)
SELECT country, count(country) as COUNT FROM Author GROUP BY country HAVING count(country) > 4

Q) Retrieve a list of employees ordered in descending order by department ID
and within each department ordered alphabetically in descending order by last name
SELECT F_NAME, L_NAME, DEP_ID
FROM EMPLOYEES
ORDER BY DEP_ID DESC, L_NAME DESC;
Q) For each department retrieve the number of employees in the department, and the average employee salary in the department. Label the computed columns in the result set as NUM_EMPLOYEES and AVG_SALARY.
Order the result set by Average Salary. Limit the result to departments with fewer than 4 employees
SELECT DEP_ID, COUNT(*) AS "NUM_EMPLOYEES", AVG(SALARY) AS "AVG_SALARY"
FROM EMPLOYEES
GROUP BY DEP_ID
HAVING COUNT(*) < 4
ORDER BY AVG_SALARY;
* Buit-in Database Functions *
# Built-in Functions
- can significantly reduce the amount of data that needs to be retrieved
- can speed up data processing
# Aggregate (Column) Functions
- Input) collection of values (e.g. entire column)
- Output) single value
- examples) SUM(), MIN(), MAX(), AVG(), etc
ex1) select SUM(COST) from PETRESCUE
ex2) select SUM(COST) as SUM_OF_COST from PETRESCUE
- can also be applied on a subset of data instead of an entire column
ex3) select MIN(ID) from PETRESCUE where ANIMAL = 'Dog'
# Scalar & String Functions (for char and varchar values)
- perform operations on every input value
- examples) ROUND(), LENGTH(), UCASE, LCASE
ex1) select ROUND(COST) from PETRESCUE
ex2) select * from PETRESCUE where LCASE(ANIMAL) = 'cat'
# Date, Time Functions
- most databases contain special datatypes for dates & times (DATE, TIME, TIMESTAMP)
- DATE: YYYYMMDD
- TIME: HHMMSS
- TIMESTAMP: YYYYXXDDHHMMSSZZZZZZ(X represents a month, Z represents microseconds)
ex1) select DAY(RESCUEDATE) from PETRESCUE where ANIMAL = 'Cat'
ex2) select COUNT(*) from PETRESCUE where MONTH(RESCUEDATE) = '05'
ex3) select (RESCUEDATE + 3 DAYS) from PETRESCUE
Q) Find how many days have passed since each RESCUEDATE till now:
ex4) select (CURRENT_DATE - RESCUEDATE) from PETRESCUE
* Sub-queries and Nested Selects *
* Sub-query) a query inside another query
SELECT COLUMN1 FROM TABLE
WHERE COLUMN2 = (SELECT MAX(COLUMN2) FROM TABLE)
- sub-queries to evaluate aggregate function = cannot evaluate aggregate functions in the WHERE clause
- have to use a sub-Select expression
- sub-queries are called 'column expressions'
SELECT EMP_ID, F_NAME, L_NAME, SALARY
FROM employees
WHERE SALARY <
(SELECT AVG(SALARY) FROM employees);
SELECT EMP_UD, SALARAY, (SELECT AVG(SALARY) FROM employees) AS AVG_SALARY
FROM employees;
# sub-queries in FROM clause (=derived Tables or Table expressions)
- substitute the TABLE name with a sub-query
SELECT * FROM
(SELECT EMP_ID, F_NAME, L_NAME, DEP_ID FROM employees) AS EMP4ALL
* Working with Multiple Tables *
Q) To retrieve only the employee records that correspond to departments in the DEPARTMENTS table
SELECT * FROM employees
WHERE DEP_ID IN ( SELECT DEPT_ID_DEP FROM departments) ;
Q) To retrieve the department ID and name for employees who earn more than $70,000
SELECT DEPT_ID_DEP, DEP_NAME FROM departments
WHERE DEPT_ID_DEP IN
( SELECT DEP_ID FROM employees
WHERE SALARY > 70000 );
- using implicit JOIN (but not explicitly using JOIN)
SELECT * FROM employees, department ;
: the result is a full join (Cartesian join) - every row in the first table is joined with every row in the second table
SELECT * FROM employees, departments WHERE employees.DEP_ID = departments.DEPT_ID_DEP;
or you can use aliases
SELECT * FROM employees E, departments D WHERE E.DEP_ID = D.DEPT_ID_DEP;
Q) To see the department name for each employee
SELECT EMP_ID, DEP_NAME FROM employees E, departments D WHERE E.DEP_ID = D.DEPT_ID_DEP;
or (column names in the select clause can be pre-fixed by aliases)
SELECT E.EMP_ID, D.DEP_ID_DEP FROM employees E, departments D WHERE E.DEP_ID = D.DEPT_ID_DEP;
* 출처) Databases and SQL for Data Science with Python (Coursera)
'Database > Fundamentals' 카테고리의 다른 글
| Databases and SQL for Data Science with Python (2/2) (from Coursera) (1) | 2022.04.19 |
|---|

댓글