* 예전 포스팅에서 모델을 평가하기 위한 여러 평가기준에 대해서 알아보았다.
→ 크게, MSE, MAE, RMSE, R^2 4가지의 평가기준에 대해서 알아보았는데, 이번에는 추가로 MAPE, MPE에 대해서 알아보려 함!
All About Evaluation Metrics(1/2) → MSE, MAE, RMSE, R^2
** ML 모델의 성능을 최종적으로 평가할 때 다양한 evaluation metrics를 사용할 수 있다고 했음! ** (supervised learning - regression problem에서 많이 쓰이는 평가지표들) - 과정 (5) - 😙 그러면 차근차..
sh-avid-learner.tistory.com

5. MAPE(Mean Absolute Percentage Error)

→ 저번 포스팅에서 배웠던 2.MAE와 개념은 거의 비슷하다. MAE를 %로 나타낸 evaluation metric이라 보면 될 것이다.
→ 그럼 percentage이므로 '무엇에 대한 무엇의 비율인가?'에 대해 정확히 알아봐야 한다.
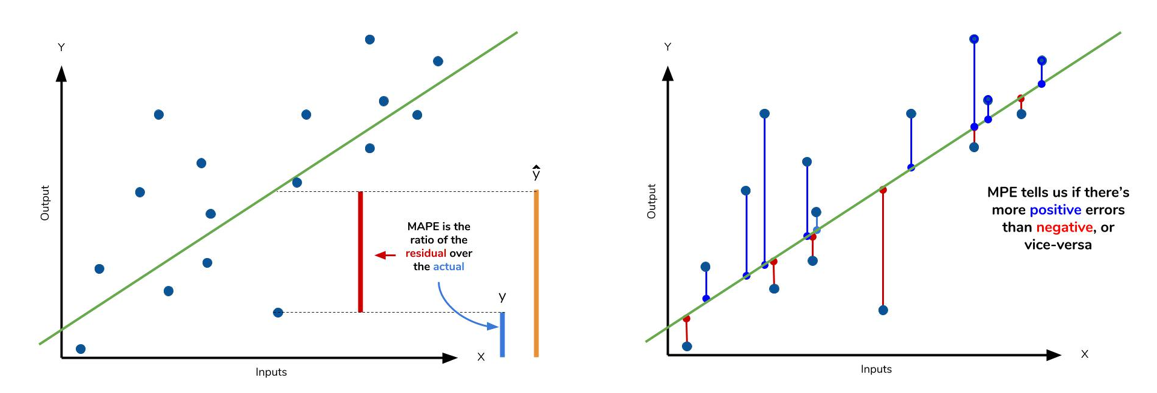
★ MAPE는 '실제값에 대한 잔차 residual(실제값 - 예측값의 절댓값)의 비율'의 평균을 %로 나타낸 것이다.
ⓐ %인 비율로 나타내기에 MAE보다 더 직관적이고 모델을 단 하나의 지표만으로 쉽게 평가를 내릴 수 있는 장점 & MAE와 마찬가지로 outlier에 좀 더 robust한 면이 있지만,
ⓑ 비율이라는 division operation 나눗셈 자체의 한계 때문에 단점이 존재한다. 분모가 0이 되는 경우, 즉 실제값이 0이 되는 case가 있다면 MAPE값 자체를 정의할 수 없음 - 따라서 MAPE를 metric로 사용한다면 실제값이 0이 되는 data가 존재하는 지 무조건 따져야 함!
ⓒ 예측값인 y hat 자체가 값이 매우 크면 기존 actual value 값과 상관없이 끝없이 MAPE 수치 자체 크기가 커진다. (y hat 값이 매우 크면 %로 따지는 의미 상실!)
ⓓ negative error (y < y hat)인 경우, 즉 기존 y가 있는데 예측값이 더 크게 측정되는 경우가, positive error(예측값이 더 작게 측정되는 경우)보다 페널티 부과 정도가 더 심하다 (심하기 때문에 위 ⓒ에서 언급한 것처럼 MAPE 수치 자체 크기가 커짐 - upper limit이 존재하지 않음)
→ 따라서 '예측값/실제값'인 비율에 log를 취해 penalty 정도를 줄이는 방법이 있다.
→ MAPE값이 작게 측정될수록 더 좋은 성능을 나타낸다.
👍 그럼 어떤 경우에 MAPE 지표를 쓸까?
▩ 실제값이 0이 아닌 dataset에서, 예측할 수 있는 범위가 실제값을 넘어갈 수 없는 환경인 곳에서, 최대치인 예측값을 향해 실제값이 얼마나 측정이 되었는지 이 error들을 측정할 때 MAPE 지표를 쓸 수 있다. or 실제값을 예측값이 넘어가지만, 예측값을 크게 넘어가는 값이 존재하지 않는다면 MAPE 지표 %를 통해 좀 더 직관적이게 performance 체킹이 가능하다 (만약에 크게 넘어간다 해도 log를 취하는 형식으로 그 penalty를 일부 부과해 줄여주는 방법이 있다.)
6. MPE(Mean Percentage Error)
→ MAPE와 매우 비슷! 단지 연산과정에서 절댓값이 안 들어갔을 뿐이다.
→ 절댓값이 들어가지 않은 식이기 때문에, negative error와 positive error 값 그 자체로 섞여서 얼마나 모델의 성능이 좋은 지 확인하기는 어렵다. 하지만, MPE 값을 통해 negative인지 positive인지 error가 치우친 방향을 알 수 있으며, 즉 해당 model이 overestimate했는지, underestimate했는지 대략적인 estimation이 가능하다는 매우 파워풀한 장점을 가지고 있는 평가지표!
- (좌) MAPE / (우) MPE -
* 정리
🙌 총 5가지의 평가지표를 재정리해보자면,,
| error 지표 | operation 연산 | outlier 영향? |
| MSE | square | o |
| MAE | absolute value | x |
| RMSE | square | o |
| MAPE | absolute value | x |
| MPE | - | x |
🙌 결국 많이 경험해보고 dataset과 model에 맞게 알맞게 적재적소에 집어넣어 metric의 효용성을 따져봐야 한다.
* 출처1) https://www.dataquest.io/blog/understanding-regression-error-metrics/
* 출처2) https://en.wikipedia.org/wiki/Mean_absolute_percentage_error
'Machine Learning > Fundamentals' 카테고리의 다른 글
| Adjusted R-Squared vs. R-Squared (0) | 2022.06.19 |
|---|---|
| Unsupervised Learning (0) | 2022.06.03 |
| PCA(w/code) (0) | 2022.05.31 |
| PCA(concepts) (0) | 2022.05.30 |
| Feature Selection vs. Feature Extraction (0) | 2022.05.18 |

댓글