1. 개론
→ ML은 빅데이터를 분석할 수 있는 강력한 tool의 일종이다. 기존 통계학 및 시각화로는 해결할 수 없는 한계를 보완함!
👏 데이터를 기반으로 앞으로의 미래를 예측하는 기법
👋 주어진 데이터가 있으면 이 데이터의 패턴을 파악
🖐 주어진 데이터를 활용한 추천 시스템 개발!
→ 위 세 가지의 여러 활동들을 ML을 통해서 구현할 수 있다. 기계가 이런 활동을 알아서 학습하게끔 스스로 그런 능력을 갖게 하는 것!
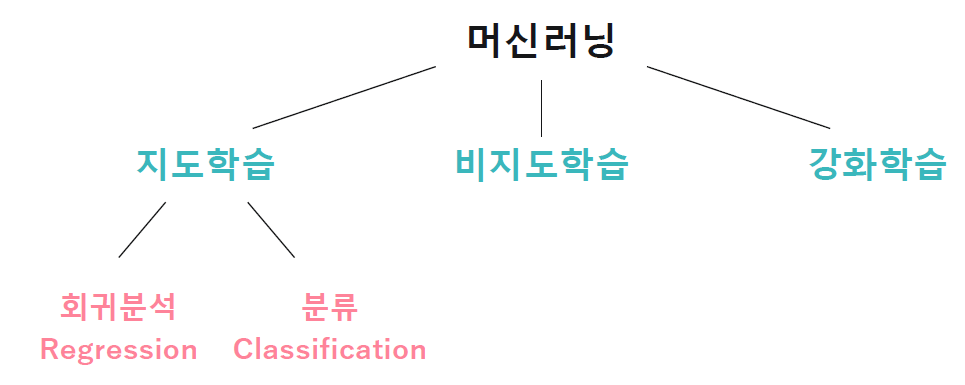
→ ①지도학습은 정답이 주어져있고, ②비지도학습은 정답이 주어져 있지 않다.
→ ③강화학습을 통해 기계가 스스로 학습이 가능하게 함. (학습을 수행하기 위한 데이터 x - 알아서 데이터를 생성)
2. ML을 위한 data (+EDA) 간단 정리
Intro + Aesthetics, Data Type & Scales (source from <Fundamentals of DV by Claus O.Wilke>)
* Intro "Data visualization is part art and part science. The challenge is to get the art right without getting the science wrong and vice versa. A data visualization first and foremost has to accu..
sh-avid-learner.tistory.com
* visualization posting에서 총 4개의 data type에 대해 정리해본 적이 있다 *

> 즉, data type을 자세히 위와 같이 4개의 type으로 나눌 수 있으며, categorical의 nominal & ordinal / 그리고 numerical의 continuous data의 경우 각각 어떤 형태로 descriptive statistics를 보여줄 수 있을 지도 배웠다.
EDA - Exploratory Data Analysis
1. concepts & goals → 탐색적 데이터 분석 - 수집한 데이터를 본격적으로 분석하기 전에 자료를 직관적으로 바라보는 과정이 필요한데, 이때 EDA를 사용한다 - 데이터 분석의 한 종류로 복잡한 모
sh-avid-learner.tistory.com
Q. 여기서 descriptive statistics & inferential statistics의 차이점은?
descriptive statistics & inferential statistics
statistics 통계학을 배운다면 반드시(?) 구분해서 알아야 할 '기술통계치' & '추론통계치'!! 1. descriptive statistics(기술통계치) 'summarizes the characteristic of a data set' ≫ 주어진 data를 'descri..
sh-avid-learner.tistory.com

3. ML을 위한 data 전처리 간단 정리
> 주어진 data를 그대로 쓸 경우는 거의 없고 직접 입맛에 맞게, 목적에 맞게 전처리를 해야하는 경우가 생기기 마련
> ML 모델이 이해하게끔 적절한 input 형태로 변환해야 한다
① categorical data의 경우 알맞은 encoding 기법을 사용 (+더미 기법)
(nominal, ordinal에 따라 다르므로 적절한 기법을 골라서 사용해야 한다! 추후 여러 기법 포스팅 예정)
② numerical data의 경우 normalization, standardization 과정들을 거침 or 범주로 표현하는 게 더 중요한 의미를 가지면 범주(수치형)로 바꿈
③ 결측값 처리) 존재하는 sample을 삭제하거나, 다른 임의의 값으로 대체, 또는 많이 존재하는 값으로 대체하는 등 여러 방법이 있음
④ 이상치 처리) 일반적으로 이상치는 제거하며, 탐지방법은 통계지표나 box plot 등 EDA 시각화 과정에서 육안으로 판단, 또는 ML 기법 적용 결과 이상치 추정되는 결과를 보고 판단하는 방법들이 있다.
(+) 이후 전처리가 완료되면, test & train & validation으로 이렇게 주로 3개의 data set으로 나누어 ML을 실시함!
4. 여러 ML model 소개 posting
👏 blog에서 다룬 다양한 여러 model들을 소개한다 (지속 업뎃 예정) 👏
- 단순선형회귀 -
Simple Linear Regression (concepts)
** 우리는 저번시간에 Supervised Learning - Regression - Linear Regression까지 concepts에 대해 배웠다 (↓↓↓↓↓↓ 하단 포스팅 참조 ↓↓↓↓↓↓) ML Supervised Learning → Regression → Linear Regr..
sh-avid-learner.tistory.com
- 다중선형회귀 -
Multiple Linear Regression Model (concepts+w/code)
✌️ 저번 시간에 feature가 1개인 단순선형회귀모델에 대해서 배웠다 ✌️ - 이론(개념) - Simple Linear Regression (concepts) ** 우리는 저번시간에 Supervised Learning - Regression - Linear Regression..
sh-avid-learner.tistory.com
- 릿지회귀 -
(L2 Regularization) → Ridge Regression (concepts)
** 우리는 저번 포스팅에서 Supervised Learning 중 Regression의 일종인 'linear regression'에 대해 학습했다. ☝️ 위 그림에서 보다시피 linear 선형 regression으로는 많은 종류의 model이 있음을 확인할..
sh-avid-learner.tistory.com
- 로지스틱회귀 -
Logistic Regression Model (concepts)
** ML 개요 포스팅에서 다룬 'supervised learning'은 아래와 같은 절차를 따른다고 했다 (↓↓↓↓하단 포스팅 참조 ↓↓↓↓) ML Supervised Learning → Regression → Linear Regression 1. ML 기법 구분 💆..
sh-avid-learner.tistory.com
- 다항회귀 -
Polynomial Regression Model
* Linear Regression Model - 즉, y 종속변수와 x 독립변수(1개 또는 2개 이상)들 간의 관계가 선형인 경우를 뜻한다. 즉, x 독립변수의 증감 변화에 따라 y도 이에 상응하여 증감이 일정한 수치의 폭으로
sh-avid-learner.tistory.com
- 결정트리 -
Decision Trees (concepts)
'Decision Trees (DTs) are a non-parametric supervised learning method used for classification and regression. The goal is to create a model that predicts the value of a target variable by le..
sh-avid-learner.tistory.com
5. ML cheat sheets

'Machine Learning > Fundamentals' 카테고리의 다른 글
| One-Hot encoding (0) | 2022.04.17 |
|---|---|
| Cross-Validation (concepts + w/code) (0) | 2022.04.17 |
| Overfitting/Underfitting & Bias/Variance Tradeoff (0) | 2022.04.17 |
| All About Evaluation Metrics(1/2) → MSE, MAE, RMSE, R^2 (0) | 2022.04.16 |
| Baseline Model (0) | 2022.04.13 |

댓글