😼 저번 포스팅에서 Ridge 회귀가 무엇인지 개념에 대해 정확히 알아보았다 😼
(L2 Regularization) → Ridge Regression (concepts)
** 우리는 저번 포스팅에서 Supervised Learning 중 Regression의 일종인 'linear regression'에 대해 학습했다. ☝️ 위 그림에서 보다시피 linear 선형 regression으로는 많은 종류의 model이 있음을 확인할..
sh-avid-learner.tistory.com
→ 이젠 Ridge 회귀를 실제 python code로 구현해서 얼마나 model이 잘 예측을 하는지, 과연 과적합에서 벗어나 더 나은 model을 만들 수 있는 건지 이번 포스팅을 통해 알아보려 한다
→ Ridge 모델을 만드는 함수는 크게 Ridge와 RidgeCV로 나뉜다. 각각에 대해서 알아보자
1. Ridge
▤ Ridge docu ▤
https://scikit-learn.org/stable/modules/generated/sklearn.linear_model.Ridge.html
class sklearn.linear_model.Ridge(alpha=1.0, *, fit_intercept=True, normalize='deprecated', copy_X=True, max_iter=None, tol=0.001, solver='auto', positive=False, random_state=None)
👉 'Linear least squares with l2 regularization. Minimizes the objective function(cost function이라고도 하며 아래 bold체) This model solves a regression model where the loss function is the linear least squares function and regularization is given by the l2-norm. Also known as Ridge Regression or Tikhonov regularization. This estimator has built-in support for multi-variate regression(다중 회귀에도 적용 가능얘기) (i.e., when y is a 2d-array of shape (n_samples, n_targets)'
" ||y - Xw||^2_2(SSR) + alpha * ||w||^2_2(L2-norm) "
- 일부 중요 parameter를 보면 .. -
→ alpha) (default = 1.0) 'Regularization strength; must be a positive float. Regularization improves the conditioning of the problem and reduces the variance of the estimates. Larger values specify stronger regularization.'
= concept 포스팅에서 다룬 penalty 부과 정도 lambda 값을 말한다
→ max_iter & solver - 내부 data type에 따라 ridge 구하는 최적의 연산법을 auto 자동으로 찾아주는데, 이 때의 연산법을 임의로 지정해서 해당 연산법으로 ridge를 구하게 설정할 수 있다. (max_iter는 이 때 연산법 반복 횟수)
(- 다양한 종류의 solver가 있으나 너무 심화 내용이라 pass - 😅)
「alpha 증가에 따른 Ridge 선형모델 변화 시각화 👀 」
→ 우리는 alpha(즉 lambda)값에 따라 penalty의 크고 작음에 영향을 줘서 Ridge 모델이 기존 SLR(Simple Linear Regression) 모델의 과적합성을 해결하고자, 즉 더 generalized된 model을 만들 수 있다고 언급했다.
→ 우리는 Ridge()를 사용하여 여러 alpha값을 집어넣고 각 alpha값을 넣은 Ridge 모델을 모두 시각화하여 각각의 차이점을 비교해볼 수 있다!
1> iris dataset 준비
2> SLR모델과의 비교를 위해 y종속변수는 'petal length' & x독립변수는 'sepal length' 1개 한정
3> alpha값은 0부터 20, 40, 60, 80 까지 총 5가지의 Ridge model 준비
(→여기서 alpha가 0일때는 penalty를 아예 부과하지 않겠다는 뜻으로 SLR model이 곧 Ridge model)
4> 총 5개의 Ridge model을 시각화하여 육안상 차이점을 확인해보자
import matplotlib.pyplot as plt
import matplotlib
from sklearn.linear_model import Ridge
import seaborn as sns
import numpy as np
import pandas as pd
#preprocessing
df = sns.load_dataset('iris')
df.drop(columns=['sepal_width','species','petal_width'],inplace=True)
plt.figure(figsize=(6,7))
title_font = {
'fontsize': 16,
'fontweight': 'light'
}
plt.title('Sepal Length vs. Petal Length - SLR vs Ridge', pad=15, fontdict=title_font)
plt.xlabel('Sepal Length', labelpad=10, size=13)
plt.ylabel('Petal Length', labelpad=10, size=13)
plt.scatter(df['sepal_length'], df['petal_length'],color = '#C6492B')
x_lim = plt.xlim()
alphas = np.arange(0,100,20)
for alpha in alphas:
#get a Ridge model
ridge = Ridge(alpha=alpha)
#fitting
ridge.fit(df[['sepal_length']], df['petal_length'])
slope = ridge.coef_
intercept = ridge.intercept_
x = x_lim
#visualization
plt.plot(x, slope*x + intercept, linewidth = 3, label = f'alpha {alpha}')
plt.grid(True, linestyle='--')
plt.legend()
plt.style.use('default')
plt.axhline(df['petal_length'].mean(), 0, 1, color = 'red', linewidth=3)
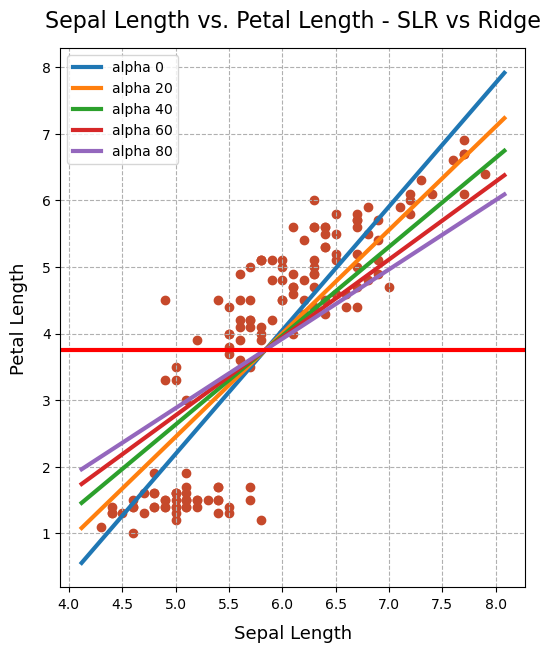
→ 해석 1> alpha가 증가할수록 기울기가 감소하는 것을 볼 수 있다. 이는 lambda값을 증가시킨다면 cost function을 최소화하기 위한 목적으로 회귀계수제곱합을 감소시켜야 하므로 - 해당 기존 SLR 모델에서의 회귀계수인 기울기값을 결과적으로 감소시킨 효과
→ 해석 2> 그러나 alpha를 점점 증가시킬수록 SLR model의 basline model에 점점 가까워지는 것을 확인할 수 있다. 따라서 어느 정도의 시점에서 멈춰야 한다!
🙏 즉, 우리는 최적의 alpha를 구할 수 있어야 한다 🙏
→ alpha 후보값들을 모두 ridge에 대입해 가면서 cross-validation 기법으로 최적의 alpha를 찾아야 한다!
(최적의 alpha 찾는 기준은 evaluation metrics (scoring system)에 의거하여 찾음)
(*CV 기법 관련 포스팅은 하단 참조 ↓↓↓↓)
Cross-Validation (concepts)
* 머신러닝을 위해서 무.조.건. 알아야 하는 CROSS-VALIDATION! 간단히 개념만 알아보ZA * - 2번 과정 - model selection에서 주로 많이 쓰이는 cross-validation 기법 - 🧐 PURPOSE? 'The purpose of cross..
sh-avid-learner.tistory.com
→ 여러 alpha 후보군들을 넣어서 알아서 최적의 alpha를 찾아 Ridge model을 만들어주는 함수가 따로 존재한다! - RidgeCV
2. RidgeCV
▤ RidgeCV docu ▤
class sklearn.linear_model.RidgeCV(alphas=(0.1, 1.0, 10.0), *, fit_intercept=True, normalize='deprecated', scoring=None, cv=None, gcv_mode=None, store_cv_values=False, alpha_per_target=False)
👉 'Ridge regression with built-in cross-validation' - 여러 alpha값들을 list 형태로 alphas에 집어넣으면 해당 alpha 중 최적의 alpha를 built-in cv기법(Leave-One-Out CV)을 사용하여 찾는다. 여기서 scoring 인자에 원하는 metrics 종류를 집어넣어 최적의 alpha를 어떤 지표로 찾는 지 수동으로 넣을 수 있다.
→ cv인자) 몇 fold의 cross-validation 사용할 지 결정 (10을 권장)
→ alphas인자) 검증하고 싶은 alpha들 list 형태로 집어넣기
→ scoring 인자) 최적의 alpha를 구하기 위해 사용하는 scroing evaluation metrics
- default는 None) 'If None, the negative mean squared error if cv is ‘auto’ or None (i.e. when using leave-one-out cross-validation), and r2 score otherwise.' = '즉 cv값이 없으면 NMSE를 사용하나 cv값이 명시되어 있으면 r2값 사용'
> 여기서 NMSE는 MSE값에 음수(-)를 곱한 것일 뿐 - 즉 MSE와 반대로 NMSE가 커지는 방향 쪽이 바람직함!
(evaluation metrics 관련 포스팅은 아래 참조 ↓↓↓↓)
All About Evaluation Metrics(1/2) → MSE, MAE, RMSE, R^2
** ML 모델의 성능을 최종적으로 평가할 때 다양한 evaluation metrics를 사용할 수 있다고 했음! ** (supervised learning - regression problem에서 많이 쓰이는 평가지표들) - 과정 (5) - 😙 그러면 차근차..
sh-avid-learner.tistory.com
+) 추가로 model attributes로 best_score_이 있는데 해당 attribute를 통해 최적의 alpha를 구할 때 사용한 최적의 score값을 따로 출력할 수 있다
> 위 iris dataset 예를 그대로 가져와서 총 7개의 alpha 중 최적의 alpha를 5-folds CV를 이용해 찾아보면.. (NMSE scoring system)
(df를 train과 test로 나누고 ridge model에 train data를 fitting했다)
train = df.sample(frac=0.75,random_state=1)
test = df.drop(train.index)
target = 'petal_length'
## X_train, y_train, X_test, y_test 데이터로 분리
X_train = train.drop(columns=target)
y_train = train[target]
X_test = test.drop(columns=target)
y_test = test[target]
from sklearn.metrics import mean_squared_error, r2_score
from sklearn.linear_model import RidgeCV
alphas = [0.01, 0.05, 0.1, 0.2, 1.0, 10.0, 100.0]
ridge = RidgeCV(alphas=alphas, cv=5)
#fitting
ridge.fit(X_train, y_train)
print(ridge.coef_, ridge.intercept_, ridge.alpha_)
print(ridge.best_score_)
#[1.85727652] -7.153726228538956 1.0
#0.7520930909807484
> alpha가 1일 때이며, y =1.85727652x -7.153726228538956에 해당하는 직선이다.
→ 해당 alpha들 중 한정해서 최적의 Ridge를 구한 것이기 때문에 만약 SLR & MLR 모델에서 과적합이 발생했다면 다양한 alpha를 집어넣어 정밀성을 높일 필요가 있다👏
- 이 때 최적의 alpha를 찾기 위해 수동으로 여러 alpha에서 구하는 대신 GridSearchCV를 사용하기도 한다 (추후 포스팅 예정)
> Q.) 그러면 과연 기존 SLR 모델보다 Ridge 적용한 후의 모델 성능이 더 좋아졌을까?
→ test set을 적용해보자
1) ridge일 때의 r2_score & MSE
#predicting
y_test_pred = ridge.predict(X_test)
print(r2_score(y_test, y_test_pred), mean_squared_error(y_test, y_test_pred))
#0.7288552126544037 0.7451543211624959
2) SLR 모델일 때의 r2_score & MSE
from sklearn.linear_model import LinearRegression
model = LinearRegression()
model.fit(X_train, y_train)
#predicting
y_test_pred_SLR = model.predict(X_test)
print(r2_score(y_test, y_test_pred_SLR), mean_squared_error(y_test, y_test_pred_SLR))
#0.727547500747554 0.7487481471318764
💁🏻♂️ 확실히 alpha=0 즉, 기존 단순선형회귀(SLR) 모델일 때보다 r2_score값은 0.727에서 0.729로 소폭 상승했고, MSE값은 0.748에서 0.745로 약간 감소하여 조금이라도 더 성능이 좋은 모델을 만들었다고 결론을 내릴 수 있음.
즉 L2 규제가 본래의 목적을 달성한 것이다!
(본래 ridge 규제는 기존 모델이 과적합을 일으켜 너무 train data에 맞춰져 있을 때 이를 어느 정도 규제를 피하고자 하기 위해 사용한다. 따라서 다항회귀모델(선형말고도 다항모델)로 과적합을 일으킬 경우 ridge 규제를 사용하는 case가 많은 데 과연 PR 모델에 규제를 가한 결과 성능이 좋아지는 지는 다음 포스팅에서 실험해볼 예정!)
- Ridge 기초 끝! -
(이젠 다른 L1 Regularization으로 만든 LASSO와 비교해보자)
* 출처) https://www.mygreatlearning.com/blog/what-is-ridge-regression/
'Machine Learning > Models (with codes)' 카테고리의 다른 글
| Polynomial Regression Model (0) | 2022.04.24 |
|---|---|
| Logistic Regression Model (concepts) (0) | 2022.04.24 |
| (L2 Regularization) → Ridge Regression (concepts) (1) | 2022.04.19 |
| Multiple Linear Regression Model (concepts+w/code) (0) | 2022.04.17 |
| Simple Linear Regression Model (w/scikit-learn) (0) | 2022.04.16 |

댓글