🔊 저번 시간에 MLE에 대해서 배웠다. 그리고 예제로 MLE 기법을 logistic regression에 적용해 최적의 sigmoid 함수를 어떻게 구하는 지 수학적으로 수식을 통해 알아보았다.
🔊 이번 시간에는 logistic이 아닌 normal distribution에 MLE 기법을 적용해 주어진 data를 가장 잘 설명하는 normal distribution의 두 모수인 $\mu$와 $\sigma$를 찾아 최적의 normal distribution을 알아보는 시간을 가져보려 한다.
Maximum Likelihood Estimation(MLE)
🌟 로지스틱 회귀 포스팅에서 MLE기법을 통해 model을 결정한다고 하였다. 로지스틱 회귀의 식을 더 deep하게 수학적으로 들어가, 어떤 모델을 고를 지 수식으로 연산하는 과정에서 MLE가 핵심으로
sh-avid-learner.tistory.com
* normal distribution 개요>
$pr(x|\mu, \sigma)$ = $\cfrac{1}{\sigma \sqrt{2\pi}}$ $e^{-\cfrac{1}{2}(\cfrac{x - \mu}{\sigma})^2}$
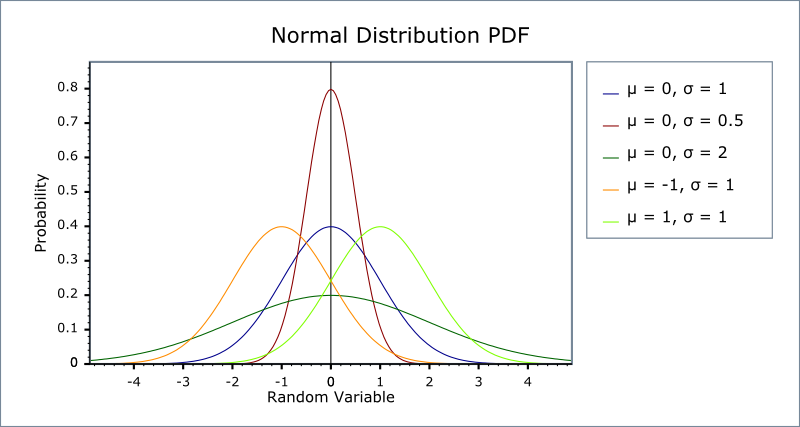
→ 위 그림에서 보듯이 distribution의 이동 방향은 $\mu$가 결정해준다. 분포 전체의 평균인 중심을 뜻한다. $\mu$ 값이 크면 오른쪽으로 이동, 작으면 왼쪽으로 이동한다.
→ distribution의 너비, 즉 양 옆으로 퍼진 정도는 $\sigma$가 결정해준다. $\sigma$ 값이 클수록 양 옆으로 퍼지고, 작을수록 위로 뾰족해진다.
🌿 우리는 해당 distribution 함수를 likelihood로 두어 해당 likelihood가 최대가 될 때의 distribution을 찾으려 한다 (두 모수 찾기)
🌿 $L(\mu, \sigma|x)$ = $\cfrac{1}{\sigma \sqrt{2\pi}}$ $e^{-\cfrac{1}{2}(\cfrac{x - \mu}{\sigma})^2}$
🌿 speculation) 주어진 x data들이 있을 때, 해당 x data들을 가장 잘 설명하는 normal distribution은 주어진 x data의 평균이 해당 distribution의 모수 $\mu$이고, 주어진 x data의 표준편차가 distribution의 $\sigma$라고 추측할 수 있다.
🌿 MLE 기법으로 증명해보자.
* using MLE>
※ 주의 - 모수가 2개 이상인 경우 각 모수별로 편미분할 때, 다른 모수는 constant 취급한 채로 편미분
① 전체 likelihood는 각 x point별 likelihood를 모두 곱한 값이다
→ $L(\mu, \sigma | x_1, x_2, ... , x_n) $ = $L(\mu, \sigma | x_1)$ x $L(\mu, \sigma | x_n)$ = $\cfrac{1}{\sigma \sqrt{2\pi}}$ x $e^{-\cfrac{1}{2}(\cfrac{x_1 - \mu}{\sigma})^2}$ x ... x $\cfrac{1}{\sigma \sqrt{2\pi}}$ x $e^{-\cfrac{1}{2}(\cfrac{x_n - \mu}{\sigma})^2}$
② 미분연산 편의를 위해 양변에 ln 로그를 취하면
→ $ln[L(\mu, \sigma | x_1, x_2, ... , x_n)]$ = $ln($$\cfrac{1}{\sigma \sqrt{2\pi}}$ x $e^{-\cfrac{1}{2}(\cfrac{x_1 - \mu}{\sigma})^2}$ x ... x $\cfrac{1}{\sigma \sqrt{2\pi}}$ x $e^{-\cfrac{1}{2}(\cfrac{x_n - \mu}{\sigma})^2}$)
③ 우변 ln을 쭉 풀고 계산하면
→ = $ln($$\cfrac{1}{\sigma \sqrt{2\pi}}$ x $e^{-\cfrac{1}{2}(\cfrac{x_1 - \mu}{\sigma})^2}$) + ... + $ln($$\cfrac{1}{\sigma \sqrt{2\pi}}$ x $e^{-\cfrac{1}{2}(\cfrac{x_n - \mu}{\sigma})^2}$)
= $ln[(2\pi\sigma^2)^{-1/2}]$ - $\cfrac{(x_1 - \mu)^2}{2\sigma^2}$$ln(e)$ + ... + $ln[(2\pi\sigma^2)^{-1/2}]$ - $\cfrac{(x_n - \mu)^2}{2\sigma^2}$$ln(e)$
= -$\cfrac{1}{2}$$ln(2\pi\sigma^2)$ - $\cfrac{(x_1 - \mu)^2}{2\sigma^2}$ + ... + -$\cfrac{1}{2}$$ln(2\pi\sigma^2)$ - $\cfrac{(x_n - \mu)^2}{2\sigma^2}$
= -$\cfrac{1}{2}$$ln(2\pi)$ -$\cfrac{1}{2}$$ln(\sigma^2)$ - $\cfrac{(x_1 - \mu)^2}{2\sigma^2}$ + ... + -$\cfrac{1}{2}$$ln(2\pi)$ -$\cfrac{1}{2}$$ln(\sigma^2)$ - $\cfrac{(x_n - \mu)^2}{2\sigma^2}$
= -$\cfrac{1}{2}$$ln(2\pi)$ -$ln(\sigma)$ - $\cfrac{(x_1 - \mu)^2}{2\sigma^2}$ + ... + -$\cfrac{1}{2}$$ln(2\pi)$ -$ln(\sigma)$ - $\cfrac{(x_n - \mu)^2}{2\sigma^2}$
④ 공통된 항들을 묶어 표현하면 ln 연산을 간단하게 완성할 수 있다.
→ = -$\cfrac{n}{2}$$ln(2\pi)$ -$nln(\sigma)$ - $\cfrac{(x_1 - \mu)^2}{2\sigma^2}$ - ... - $\cfrac{(x_n - \mu)^2}{2\sigma^2}$
⑤ (1) 이제 $\mu$에 관한 편미분을 해보면
→ $\cfrac{\partial}{\partial\mu}$ $ln[L(\mu, \sigma | x_1, x_2, ... , x_n)]$ = 0 - 0 + $\cfrac{x_1 - \mu}{\sigma^2}$ + ... + $\cfrac{x_n - \mu}{\sigma^2}$
= $\cfrac{1}{\sigma^2}$ $[(x_1 + ... + x_n) - n\mu]$
⑥ (2) $\sigma$에 관한 편미분을 해보면
→ $\cfrac{\partial}{\partial\sigma}$ $ln[L(\mu, \sigma | x_1, x_2, ... , x_n)]$ = 0 -$\cfrac{n}{\sigma}$ + $\cfrac{(x_1 - \mu)^2}{\sigma^3}$ + ... + $\cfrac{(x_n - \mu)^2}{\sigma^3}$ = -$\cfrac{n}{\sigma}$ + $\cfrac{1}{\sigma^3}$$[(x_1 - \mu)^2 + ... + (x_n - \mu)^2]$
⑦ 두 모수에의 편미분 값이 0일 때를 확인 (최대치이므로)
→ 1> 0 = $\cfrac{1}{\sigma^2}$ $[(x_1 + ... + x_n) - n\mu]$
↔ 0 = $(x_1 + ... x_n) - n\mu$
↔ $\mu$ = $\cfrac{(x_1 + ... x_n)}{n}$
→ 2> 0 = -$\cfrac{n}{\sigma}$ + $\cfrac{1}{\sigma^3}$$[(x_1 - \mu)^2 + ... + (x_n - \mu)^2]$
↔ 0 = $-n$ + $\cfrac{1}{\sigma^2}$$[(x_1 - \mu)^2 + ... + (x_n - \mu)^2]$
↔ $\sigma$ = $\sqrt{\cfrac{(x_1 - \mu)^2 + ... + (x_n - \mu)^2}{n}}$
⑧ 결과, 최적의 $\mu$는 주어진 data의 평균, 최적의 $\sigma$는 주어진 data의 표준편차임을 MLE 기법을 통해 증명하였다!
(위의 speculation이 맞았음 확인 가능)
* 출처) 갓 STATQUEST https://www.youtube.com/watch?v=Dn6b9fCIUpM
* 사진, 썸넬출처) https://www.boost.org/doc/libs/1_49_0/libs/math/doc/sf_and_dist/graphs/normal_pdf.png
'Statistics > Concepts(+codes)' 카테고리의 다른 글
| Maximum Likelihood Estimation(MLE) (1) | 2022.06.26 |
|---|---|
| Auto-correlation + Durbin-Watson test (0) | 2022.06.17 |
| Bayesian Theorem (0) | 2022.05.07 |
| distribution》poisson distribution (포아송분포) (0) | 2022.05.06 |
| distribution》binomial distribution (이항분포) (0) | 2022.05.06 |

댓글