👋🏻 저번 시간에 Logistic Regression Model이 무엇인지, 기초 개념에 대해서 학습했다. (↓↓↓↓↓↓)
Logistic Regression Model (concepts)
** ML 개요 포스팅에서 다룬 'supervised learning'은 아래와 같은 절차를 따른다고 했다 (↓↓↓↓하단 포스팅 참조 ↓↓↓↓) ML Supervised Learning → Regression → Linear Regression 1. ML 기법 구분 💆..
sh-avid-learner.tistory.com
🙏 이젠 python으로 model을 직접 구현해보려 한다!
- binary classification problem solving을 위해 필요한 모델이라 배움 -

++ scikit-learn 사용 ++
¶ sklearn.linear_model.LogisticRegression docu() ¶
class sklearn.linear_model.LogisticRegression(penalty='l2', *, dual=False, tol=0.0001, C=1.0, fit_intercept=True, intercept_scaling=1, class_weight=None, random_state=None, solver='lbfgs', max_iter=100, multi_class='auto', verbose=0, warm_start=False, n_jobs=None, l1_ratio=None)
> logistic regression 모델에 들어가는 여러 hyperparamter 조합은 추후 알아보자! (어렵다;; 😢) <
일부만 알아보자면.
→ class_weight(default None): 로지스틱 회귀에 data를 학습시킬 때 target 두 범주 비율이 매우 불균형할 경우 균일하게 학습시켜 성능을 높이는 방법이다. 'balanced'값을 넣거나 각 class 별 학습시키고 싶은 원하는 가중치를 넣으면 된다.
→ solver(default lbfgs): 문제를 최적화할 때 쓰이는 알고리즘의 종류이다. default로는 lbfgs라는 기존 BFGS 알고리즘의 limited-memory 버전인데 내가 원하는 알고리즘 종류를 선택해 최적의 모델링할 수 있게 만들어 줄 수 있다. 이 때 lbfgs는 l2 규제를 사용한다. 너무 어려운 알고리즘이 많아서 잠시 skip. (더 깊게 팔 지는 나중에 가면 알 것 같다?)
→ warm_start(default False): True로 설정하면 이미 학습했던 모델의 결과를 바탕으로 다음에 또 학습 시 학습 자료로 제공이 된다. 즉 누적해서 학습시켜주는 기능
→ max_iter(default 100): 앞에서 정한 solver algorithm을 바탕으로 알고리즘이 결과를 내기 위해 계속해서 돌아가는데 총 몇 번 돌릴 지 그 개수를 설정하는 파라미터. 100번보다 조금 더 많이 돌리면 오히려 성능이 올라가는 case가 더러 있다!
→ verbose: 모델 돌리는 과정 알아보고 싶을 때 과정들 출력해주는 인자
> 주요 method <
→ 타 모델과 마찬가지로 fitting - predicting을 위해 fit & predict method 존재
→ score method로 accuracy를 출력해준다 (classification evaluation metrics중 하나)
→ predict_proba method로 feature를 집어넣으면 각 binary class에 속할 확률을 보여준다! 즉, 더 큰 확률로 나온 값의 class로 예측됨
<Logistic Regression 예시 실습 (w/scikit-learn) (기존 절차 약간 변경)>
① 'Choose a class of model by importing the appropriate estimator class from Scikit-Learn.'
→ 어떤 model 부류를 사용할 지 모델 부류를 정한다!
(ex) 선형모델을 만들고 싶으면 sklearn의 linear_model을 import하면 됨!)
② 'Choose model hyperparameters by instantiating this class with desired values.'
→ 모델의 인자를 설정하는게 ❌ (ML term에서 통용되는 부분 - 헷갈리지 말기)
→ model 부류(class)를 선택했다면 해당 부류의 어떤 모델을 선택할 지 고르는 단계
(ex) 선형모델을 import 했다면 다양한 선형 모델 중 한 종류의 model을 import 한다! - 예를 들어 import LinearRegression)
→ 여기서 model을 고르는 과정에서 cross-validation 기법을 사용하기도 함
③ 'Arrange data into a features matrix and target vectorfollowing the discussion above.(+ 추가로 train/val/test 분리하기)'
→ 위 1.에서 배운 대로 모델에 들어갈 data 두 종류 X와 y 준비!
④ 'baseline model을 기반으로 metrics 수치 확인하기'
→ 후에 만들어진 모델 성능이 더 잘나와야 하므로 기준이 되는 baseline model을 만들고 성능을 확인하자
⑤ 'Fit the model to your data by calling the fit() method of the model instance.'
→ 이젠 주어진 X와 y를 model에 fitting해서 model 완성!
⑥ 'validation data 성능을 높이기 위해 ⑤ 과정 hyperparameter-tuning 무한반복'
→ 최종적으로 새로운 data나 test data를 model에 넣기 전에 최적의 성능을 내는 model을 만들기 위해 hyperparameter-tuning 과정 만족할 때까지 계속 진행
⑦ 'Apply the Model to new data (test data)'
≫ For supervised learning, often we predict labels for unknown data using the predict() method.
≫ For unsupervised learning, we often transform or infer properties of the data using the transform() or predict() method.
→ 지도학습, 비지도학습 학습 종류에 따라 약간 다르다! - 하튼 새로운 data를 집어넣어 완성한 모델에 의거해 예측값을 생성하자!
<예시>
Q. 신인 NBA 농구선수의 여러 스탯을 파악해 이를 바탕으로 향후 5년 내에 출전이 가능할 지의 여부를 판별하는 로지스틱 회귀 분류기를 구축하자
A. STEP-BY-STEP
①② 로지스틱 회귀 모델이라 정했음!
③ 데이터 - google dataset 참조
> feature는 농구 관련 여러 수치형 data (이름 column만 제외)
> target은 5년 내에 출전 예상한다면 1, 아니면 0인 binary class 형태
> preprocessing + train/test 분리 + X와 y분리
(간단 예제라 validation data 안 만듦)
dataset = pd.read_csv('./data/nba_logreg.csv')
dataset.dropna(inplace=True) #결측치 있는 행 삭제
dataset.drop(columns=['Name'],inplace=True) #이름 column 삭제
#train, test
from sklearn.model_selection import train_test_split
train, test = train_test_split(dataset, random_state=2)
target = 'TARGET_5Yrs'
X_train = train.drop(columns=target)
y_train = train[target]
X_test = test.drop(columns=target)
y_test = test[target]
> scaling - StandardScaler 사용
🗽 scaling 추천 이유 - logistic 회귀의 경우 모든 feature들의 단위 unit이 제각각 다르면 unit이 큰 feature와 작은 feature의 target 기여도에 차이가 날 수 밖에 없으며, 위에서 정해준 solver로 optimize하는 과정에서 converge, 즉 gradient descent가 converge 수렴하는 속도가 모든 feature가 단위가 제각각이므로 모델 성능 측정에 영향을 줄 수 밖에 없다.
🤸♂️ 따라서 우리는 scaling을 통해 모든 feature를 동일 unit 범위로 설정하여 매우 빠르고 정확하게 로지스틱 모델이 돌아가도록 알고리즘에 최적화된 조건을 제공해줘야 함!
-- 더 자세한 사항은 normalization, standardization, regularization posting 참고하기 --
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test)
④ baseline model 성능 확인하기 - 분포 높은 class 기준
#baseline 만들기
major = y_train.mode()[0]
y_pred_baseline = [major] * len(y_train)
from sklearn.metrics import accuracy_score
print("baseline model accuracy: ", accuracy_score(y_train, y_pred_baseline))
#baseline model accuracy: 0.6204819277108434
⑤ fitting
> 인자 튜닝은 특별히 하지 않았다. (⑥ hyperparameter tuning - validation 생략함)
#LR
from sklearn.linear_model import LogisticRegression
logistic = LogisticRegression()
# 학습
logistic.fit(X_train_scaled, y_train)
⑦ predicting - testing
# 예측
pred_lr = logistic.predict(X_test_scaled)
print("LR accuracy: ", accuracy_score(y_test, pred_lr))
#LR accuracy: 0.7027027027027027
🤹 modelling 결과 baseline accuracy는 약 0.62였는데 modeling accuracy는 약 0.7이 나옴 (성능 향상!)
- 로지스틱 모델 효과 증명! -
++ logistic coefficients 분석 ++
# plot logistic model coefficients
coefficients = pd.Series(logistic.coef_[0], X_train.columns)
plt.figure(figsize=(6,6))
coefficients.sort_values().plot.barh()
plt.show()
- logistic coefficients -
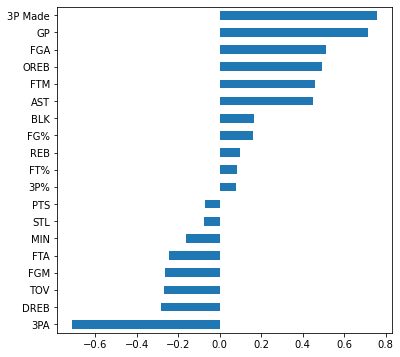
⛹️♂️ logistic의 coefficients 해석 - 해당 X feature 변수가 unit 1씩 증가하면 Odds 비(p/(1-p))가 e의 coefficients승씩 변화한다.
(scaling을 거치고 난 뒤이므로 feature별로 모두 단위가 같아서 coefficients 간 비교가 가능!)
👏 따라서 coefficient값이 0이상 양수이면 Odds 비가 1이상 = 즉 p > (1-p)로 성공확률에 더 기여하는 feature
👏 반대로 0 미만 음수인 feature는 Odds 비가 1이하 = 즉 p < (1-p)로 실패확률, 즉 class 0에 더 기여하는 feature
→ 따라서 위 모델의 경우 3P Made, GP, FGA feature가 신인 플레이어가 5년동안 잘 나간다는 점에 큰 기여. 특히 3P Made, 즉 3점 성공여부가 지대한 영향을 미친다는 걸 확인할 수 있음!
→ 3PA는 5년 커리어 여부에 제일 반대로 영향을 미치는 특성임(영향을 미치지 않는게 아님. 영향을 반대로 미침)
* 데이터 출처) https://data.world/exercises/logistic-regression-exercise-1
* 출처1) coefficients https://soobarkbar.tistory.com/12 / https://dive-into-ds.tistory.com/44
* 출처2) scaling 필요성 https://stats.stackexchange.com/questions/48360/is-standardization-needed-before-fitting-logistic-regression
'Machine Learning > Models (with codes)' 카테고리의 다른 글
| K-Means Clustering (concepts + w/code) (1) | 2022.06.08 |
|---|---|
| Decision Trees (concepts) (0) | 2022.04.27 |
| Polynomial Regression Model (0) | 2022.04.24 |
| Logistic Regression Model (concepts) (0) | 2022.04.24 |
| (L2 Regularization) → Ridge Regression (w/scikit-learn) (0) | 2022.04.20 |

댓글